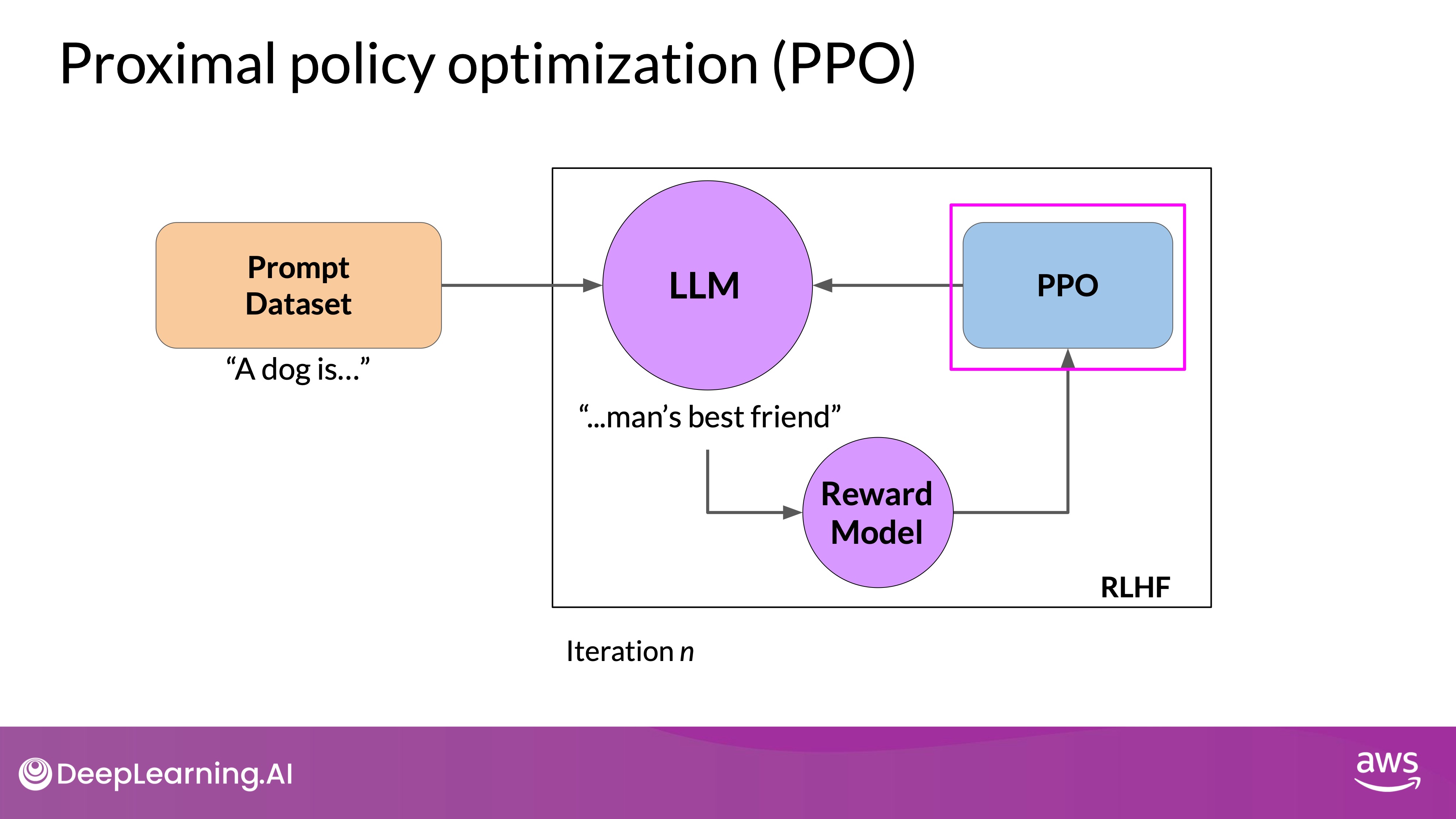
Proximal policy optimization
TL;DR - The "Proximal" in Proximal Policy Optimization refers to the constraint that limits the distance between the new and old policy, which prevents the agent from taking large steps in the policy space that could lead to catastrophic changes in behavior.
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
PPO stands for Proximal Policy Optimization. It optimizes a policy—in this case, the LLM—to better align with human preferences by making small, incremental updates within a bounded region. These small updates help ensure stable learning and avoid drastic changes that could destabilize the model. The main goal of PPO is to update the policy to maximize the expected reward, which reflects how well the model aligns with human values.
PPO Phases in LLMs
PPO operates in two main phases:
Phase 1: Experimentation, Evaluating Responses and Reward Calculation
- Prompt Generation: The initial instruct LLM generates responses to a set of given prompts.
- Reward Evaluation: These responses are evaluated by the reward model, which has been trained on human feedback to recognize criteria such as helpfulness, harmlessness, and honesty. Each completion is assigned a reward value reflecting its alignment with human preferences.
- Value function: The value function estimates the expected future rewards for these responses.
- Analogy [IMPORTANT]: This is similar to when you start writing a passage, and you have a rough idea of its final form even before you write it.
Phase 2: Policy Update (Weight Updates)
Based on the rewards and losses calculated in Phase I, the LLM's weights are updated. The updates are kept within a "trust region" to ensure the model remains stable and the changes are incremental. This process is repeated over multiple iterations or epochs, gradually improving the model's alignment with human values.
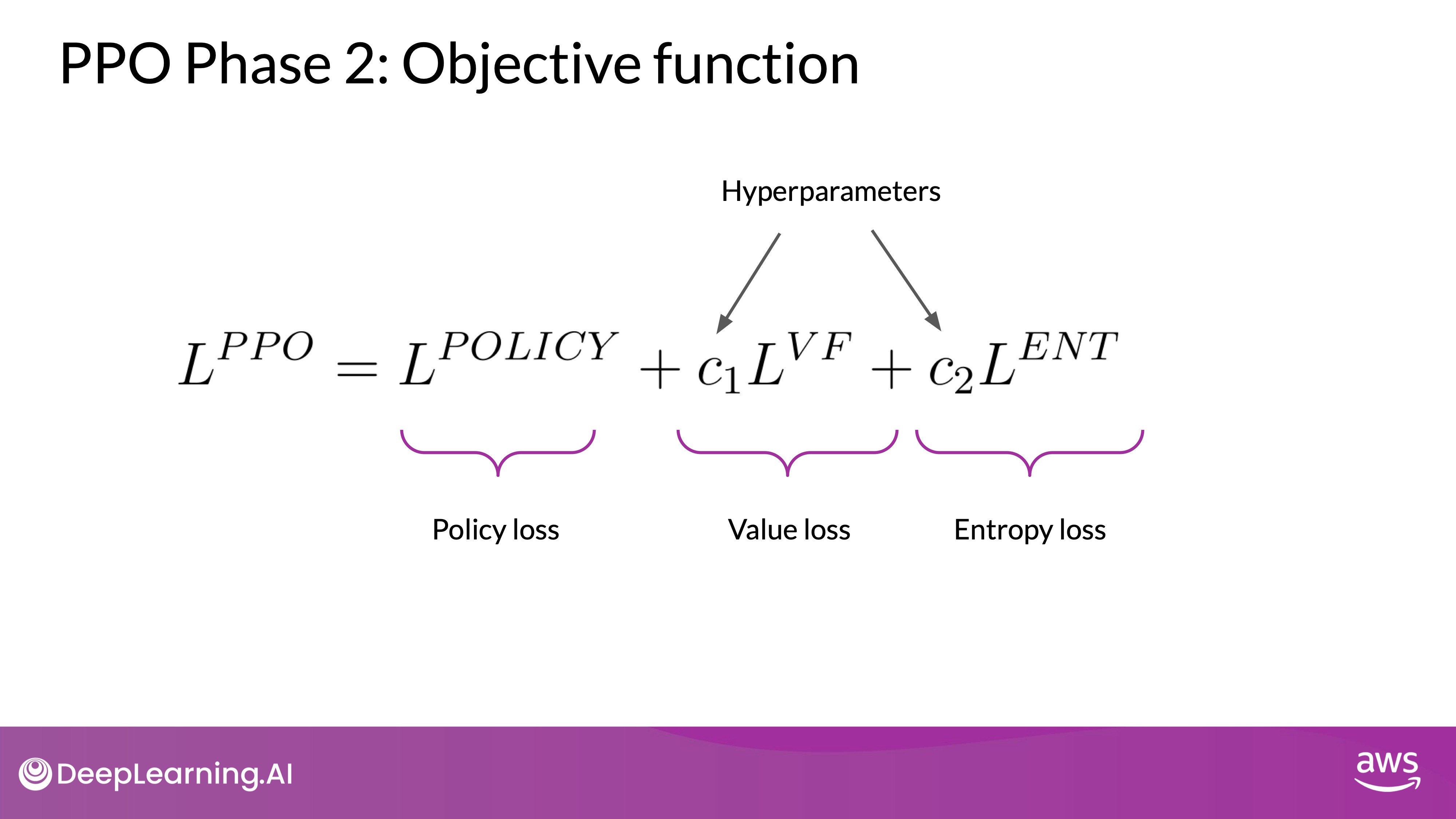
The objective is to find a policy whose expected reward is high. In other words, you're trying to make updates to the LLM weights that result in completions more aligned with human preferences and so receive a higher reward. There are 2 losses are calculated in this phase:
- Policy Loss: This component adjusts the model to maximize the expected reward based on the computed advantages.
- Entropy Loss: Calculated at this stage to encourage exploration and prevent the model from becoming too deterministic. It adds a regularization term to the loss function, which promotes generating diverse responses.
Phase 1 - Value Function
The value function and value loss are critical components in PPO:
- Value Function: This function estimates the expected total reward for a given state. As the LLM generates each token, the value function predicts the future total reward based on the current sequence of tokens.
- Value Loss: The difference between the actual future total reward and the estimated reward by the value function. Minimizing this value loss ensures that the model's future reward predictions become more accurate, leading to better-aligned completions.
Below is the high-level overview of the steps:
- Generating Responses: The LLM generates responses to prompts, which are evaluated for rewards.
- Estimating Future Rewards: The value function estimates the expected total future rewards for sequences of tokens.
- Baseline for Evaluation: The value function provides a baseline to compare the quality of completions.
- Minimizing Value Loss: The difference between actual and estimated rewards is minimized to improve accuracy.
- Advantage Estimation: Refined estimates are used in the next phase to evaluate the quality of actions.
Formula explain
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Generating Responses:
- The LLM generates responses to a given set of prompts.
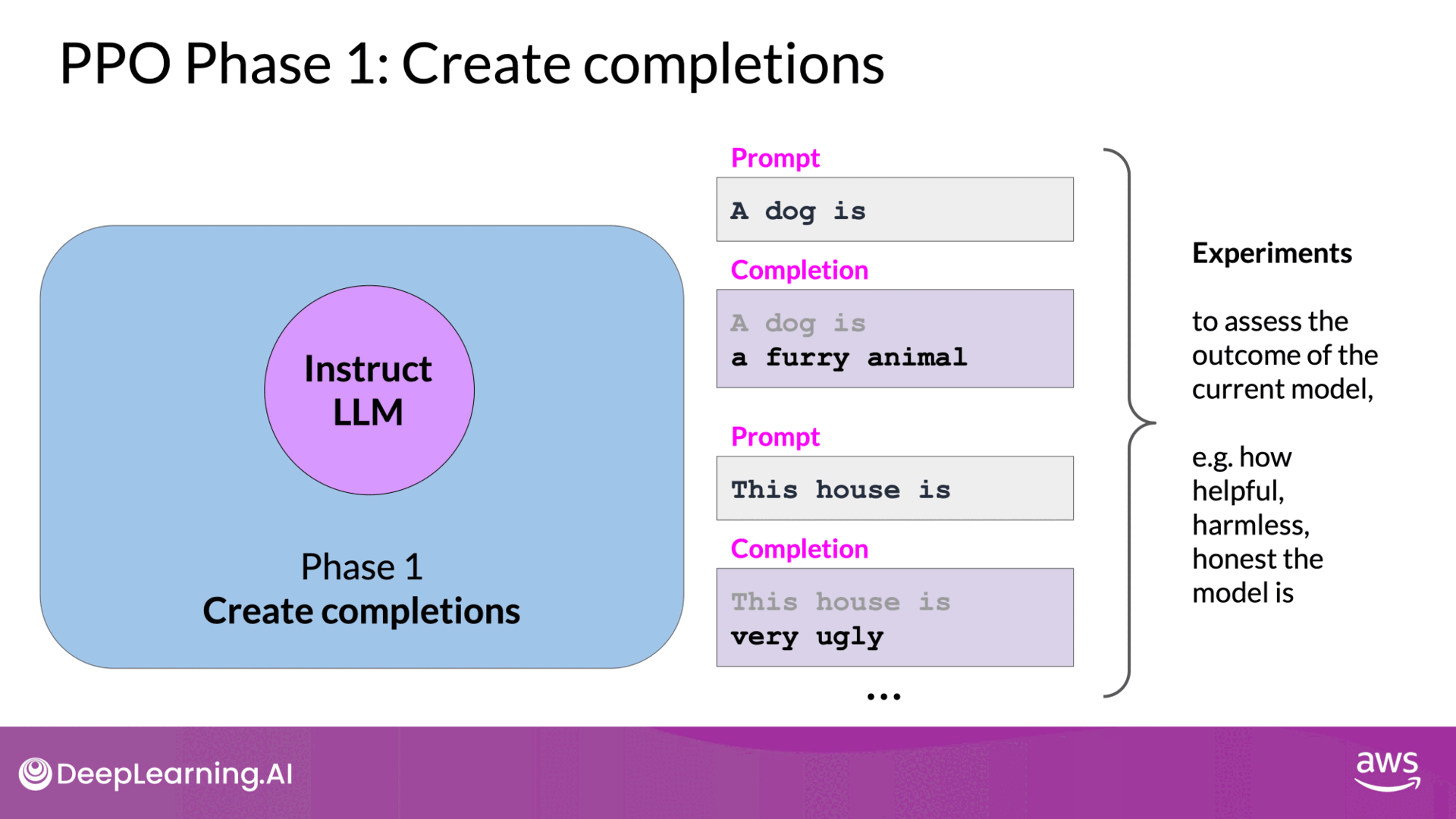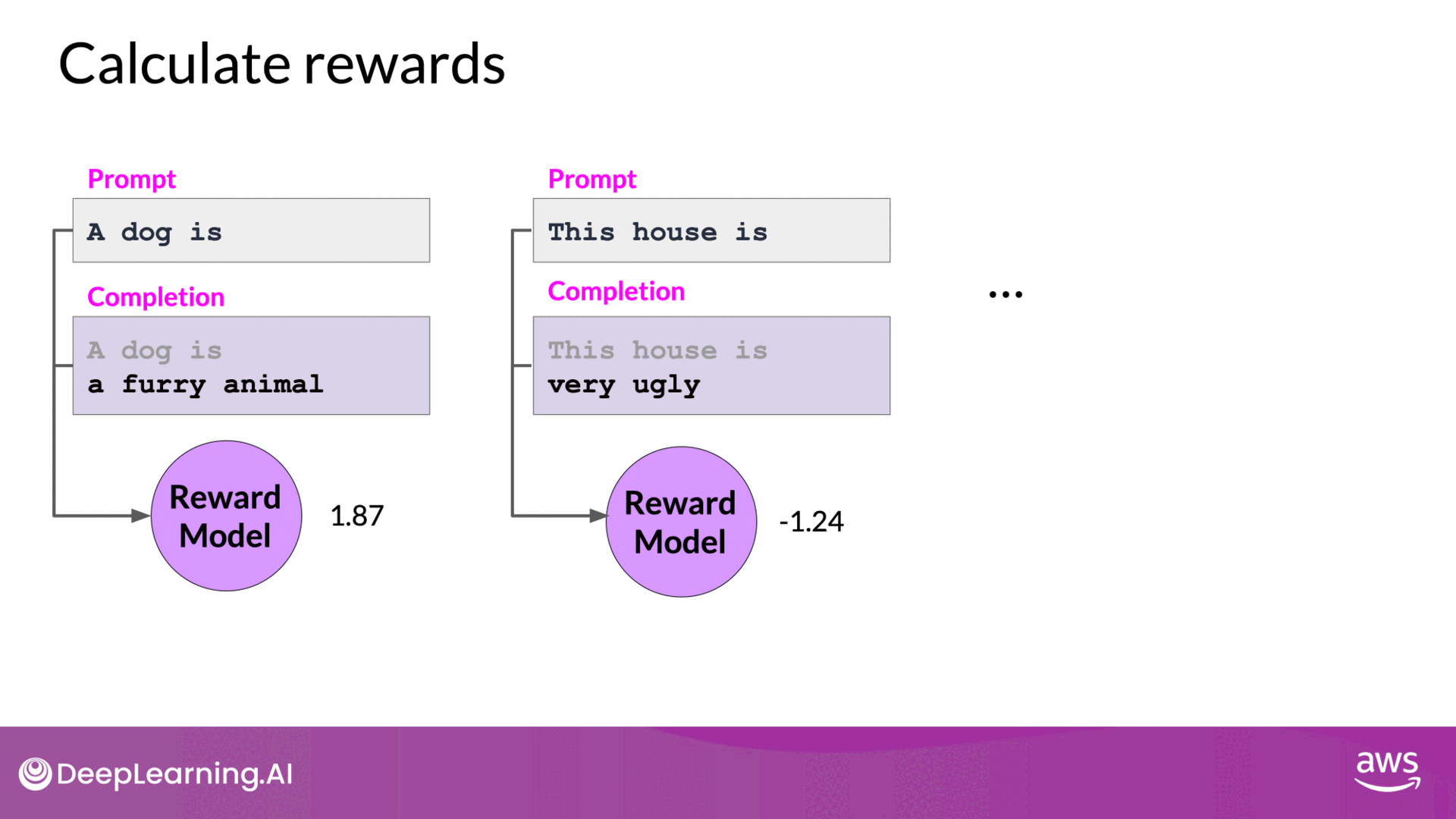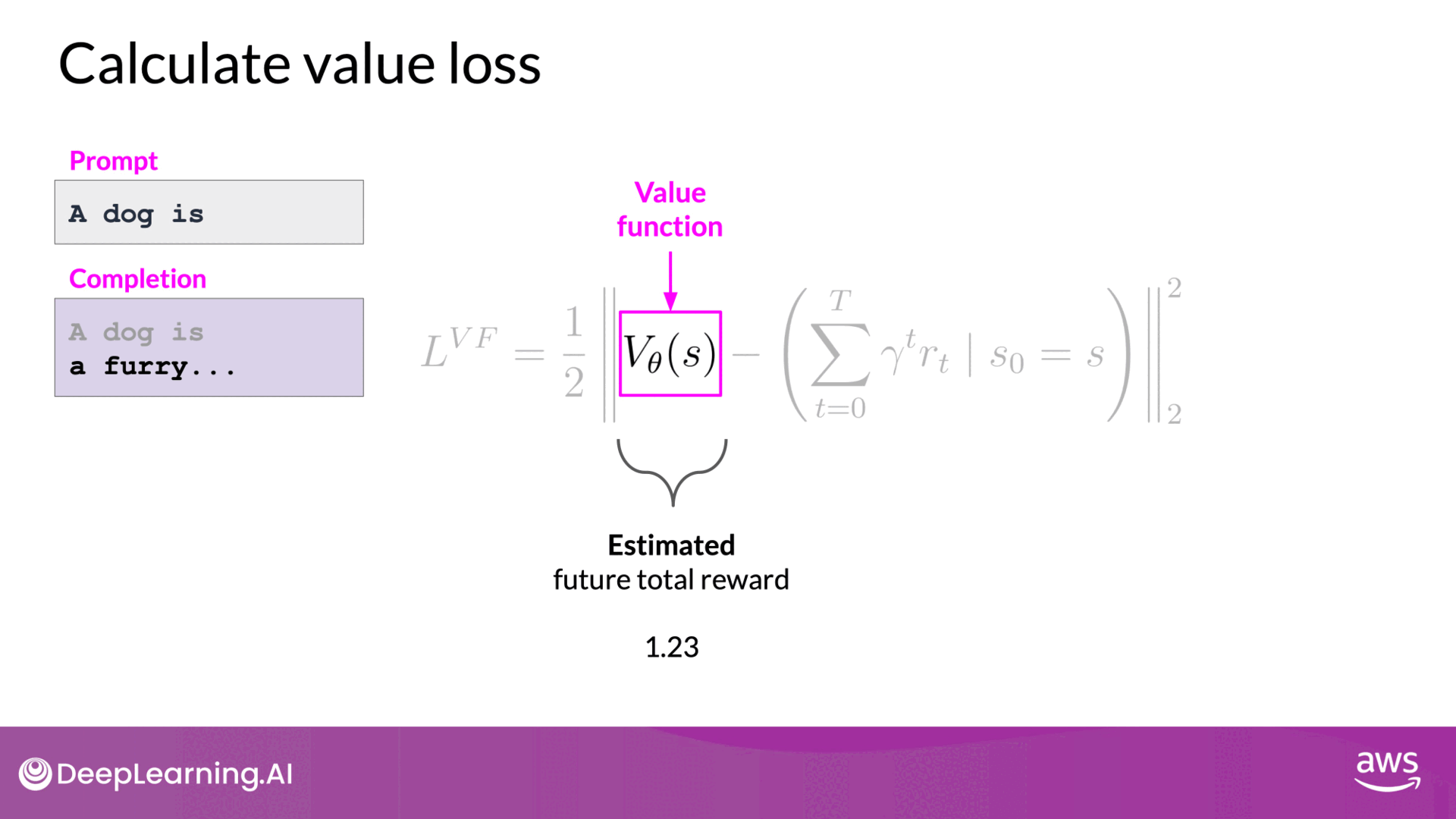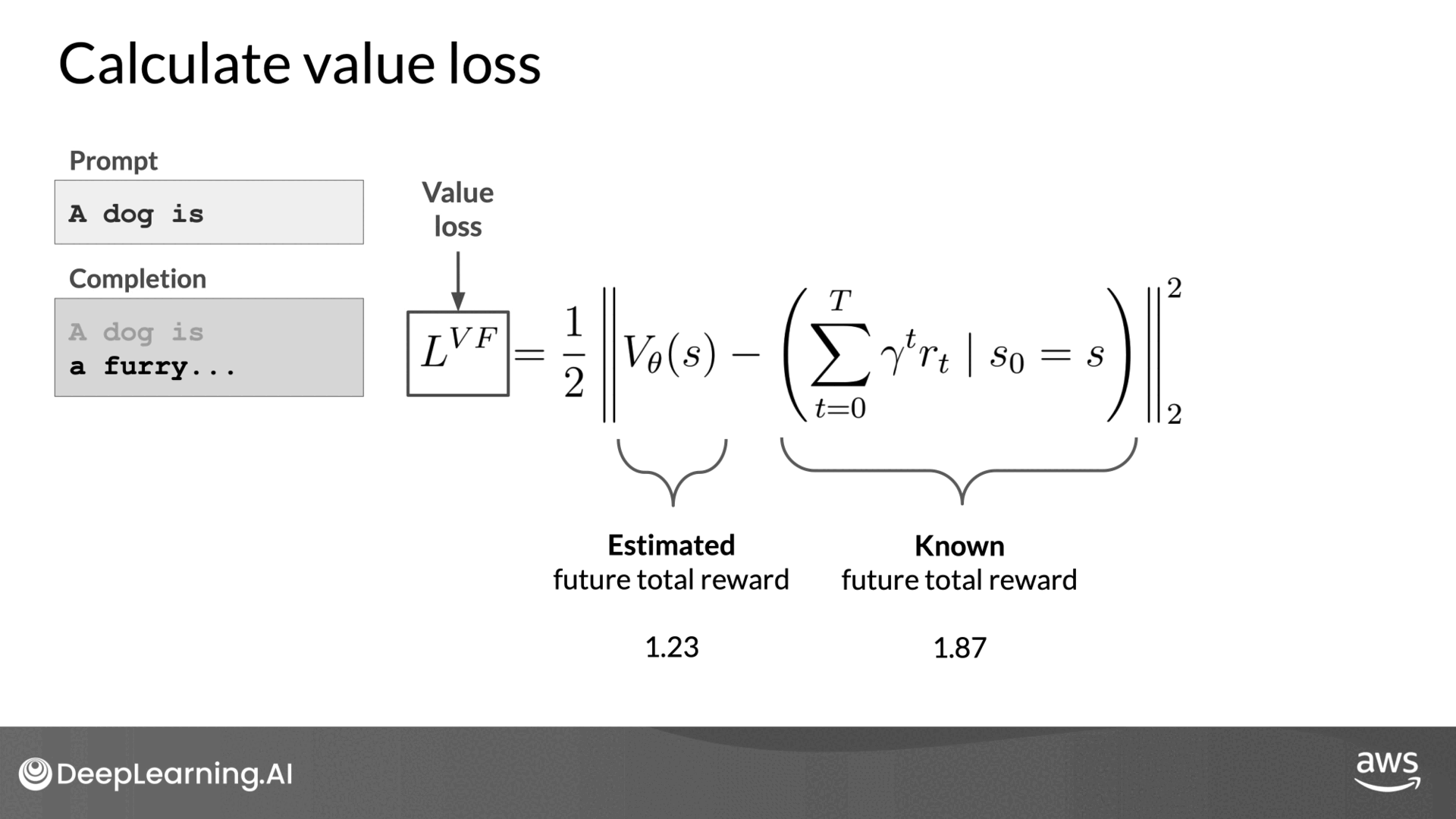
- Each completion is then evaluated by the reward model, which assigns a reward based on how well the completion aligns with human preferences. For example:
- Completion 1 might receive a reward of 1.87.
- Completion 2 might receive a reward of -1.24.
- Estimating Total Future Reward:
- The value function estimates the expected total reward for a given state .
- As the LLM generates each token in a sequence, the value function provides an estimate of the total future reward based on the current sequence of tokens.
- Baseline for Evaluation:
- The value function serves as a baseline to evaluate the quality of the generated completions.
- For instance, at a specific step in the completion, the estimated future total reward might be 0.34. After generating the next token, this estimate might increase to 1.23.
- Minimizing Value Loss:
- The goal is to minimize the value loss, which is the difference between the actual future total reward and the estimated reward by the value function.
- For example, if the actual future total reward is 1.87 and the value function's estimate is 1.23, the value loss is the difference between these two values.
- Minimizing this loss helps in making the reward estimates more accurate.
- Role in Advantage Estimation:
- The refined estimates from the value function are then used in Phase 2 for Advantage Estimation, which helps determine the quality of actions (tokens) in generating completions.
Phase 2 - Policy Loss Function
- Overview:
- Probability Expression: represents the probability of generating the next token given the current prompt.
- Advantage Term (): Estimates the quality of the current action compared to all possible actions.
- Policy Objective: Maximizes the expected reward while maintaining stability through the trust region.
- Visual Aid: Helps understand how different paths (completions) receive different rewards.
Formula explain

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
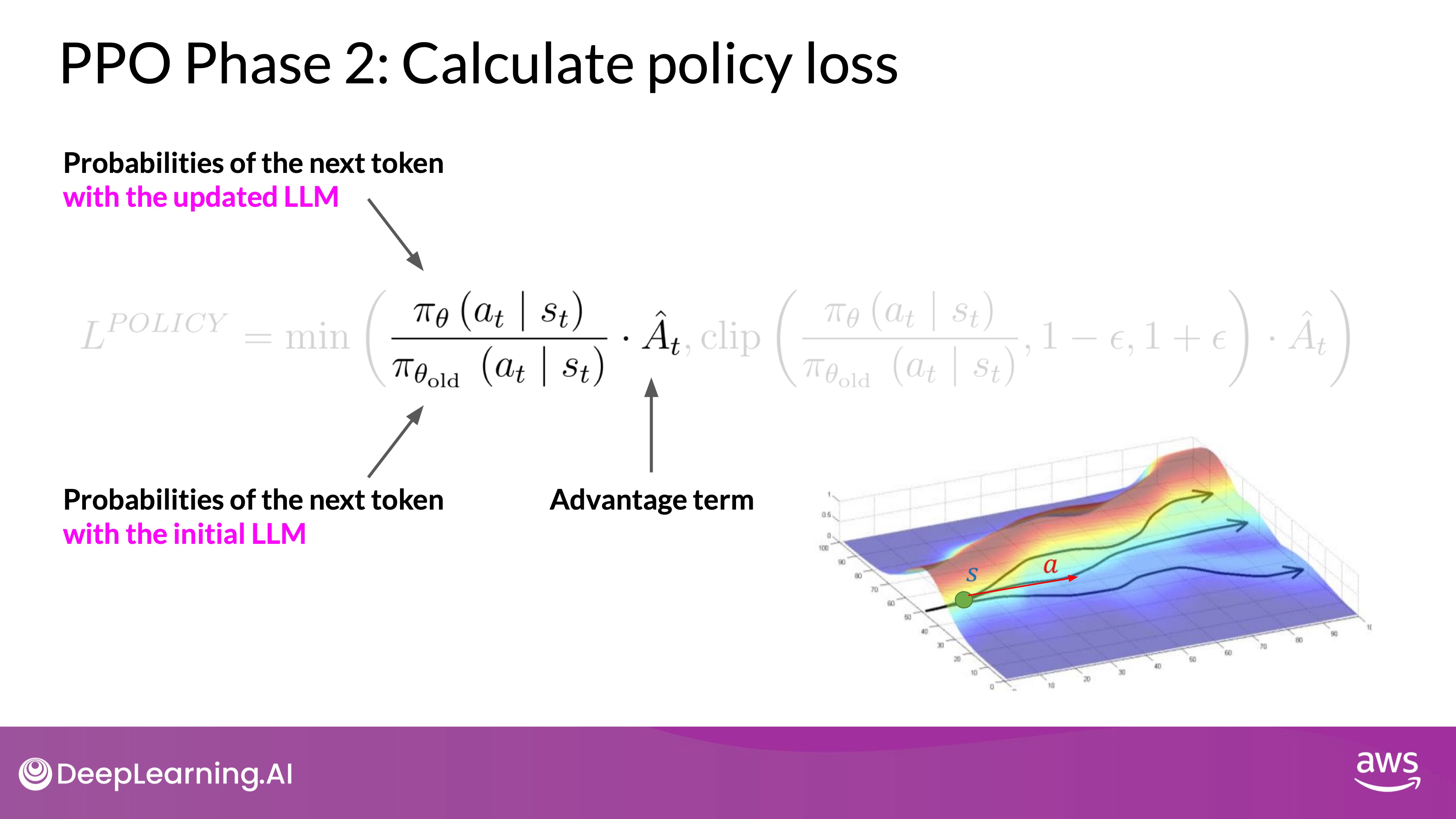
The core expression in the policy loss function focuses on the probability of generating the next token given the current prompt. In mathematical terms:
where:
- is the policy (the LLM).
- is the action, which represents the next token to be generated.
- is the state, representing the sequence of tokens generated up to time .
- Denominator & Numerator
- Denominator: The probability of the next token given the current state using the initial version of the LLM (frozen model).
- Numerator: The probability of the next token given the current state through the updated LLM, which can be adjusted to achieve better rewards.
The term (estimated advantage term) is crucial for evaluating the quality of the chosen action:
- Advantage Term (): Measures how much better or worse the current action (token) is compared to all possible actions at the given state. It is computed based on the expected future rewards of a completion following the new token. The advantage term is estimated recursively using the value function.
Visual Representation
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Imagine a prompt leading to various possible completions, represented by different paths:
- Top Path: Represents a better completion that receives a higher reward.
- Bottom Path: Represents a worse completion that receives a lower reward.
The advantage term indicates the relative quality of the current token compared to other potential tokens.
Why does maximizing this term lead to higher rewards?
Advantage Term in Simple Terms
Imagine you are playing a video game, and you have several possible moves you can make at any point. Some moves are better than others. In this context: Advantage Term tells you how good a particular move (or token in the LLM) is compared to the average of all possible moves you could make at that moment.
Positive and Negative Advantage
- Positive Advantage: If a move is better than average, it has a positive advantage. For example, if the average score for moves is 5 points, and one move gives you 8 points, the advantage for that move is +3.
- Negative Advantage: If a move is worse than average, it has a negative advantage. Using the same example, if one move gives you 2 points, the advantage for that move is -3.
Maximizing the Expression
Now, let's see why maximizing the advantage term leads to higher rewards:
- Positive Advantage (Good Move):
- When the advantage is positive, it means the current token (or move) is better than average.
- Increasing the probability of selecting this token is a good strategy because it leads to higher rewards.
- Example: If choosing word "A" in a sentence is much better than other words (it makes the sentence more meaningful), we want the model to choose "A" more often. This increases the reward.
- Negative Advantage (Bad Move):
- When the advantage is negative, it means the current token is worse than average.
- Increasing the probability of this token is a bad strategy because it leads to lower rewards.
- Example: If choosing word "B" in a sentence makes the sentence confusing or wrong, we want the model to choose "B" less often. This also aligns with maximizing the overall expression by reducing the likelihood of choosing bad tokens.
Overall Conclusion
- Maximizing the Expression: By maximizing the expression that includes the advantage term, the model learns to prefer tokens (or moves) that lead to better outcomes (higher rewards) and avoid those that lead to worse outcomes (lower rewards).
- Better Aligned Model: This process helps in creating a model that makes better decisions, resulting in completions that are more aligned with human preferences, like being more helpful, honest, and harmless.
Trust Region
Understanding the Trust Region in PPO
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
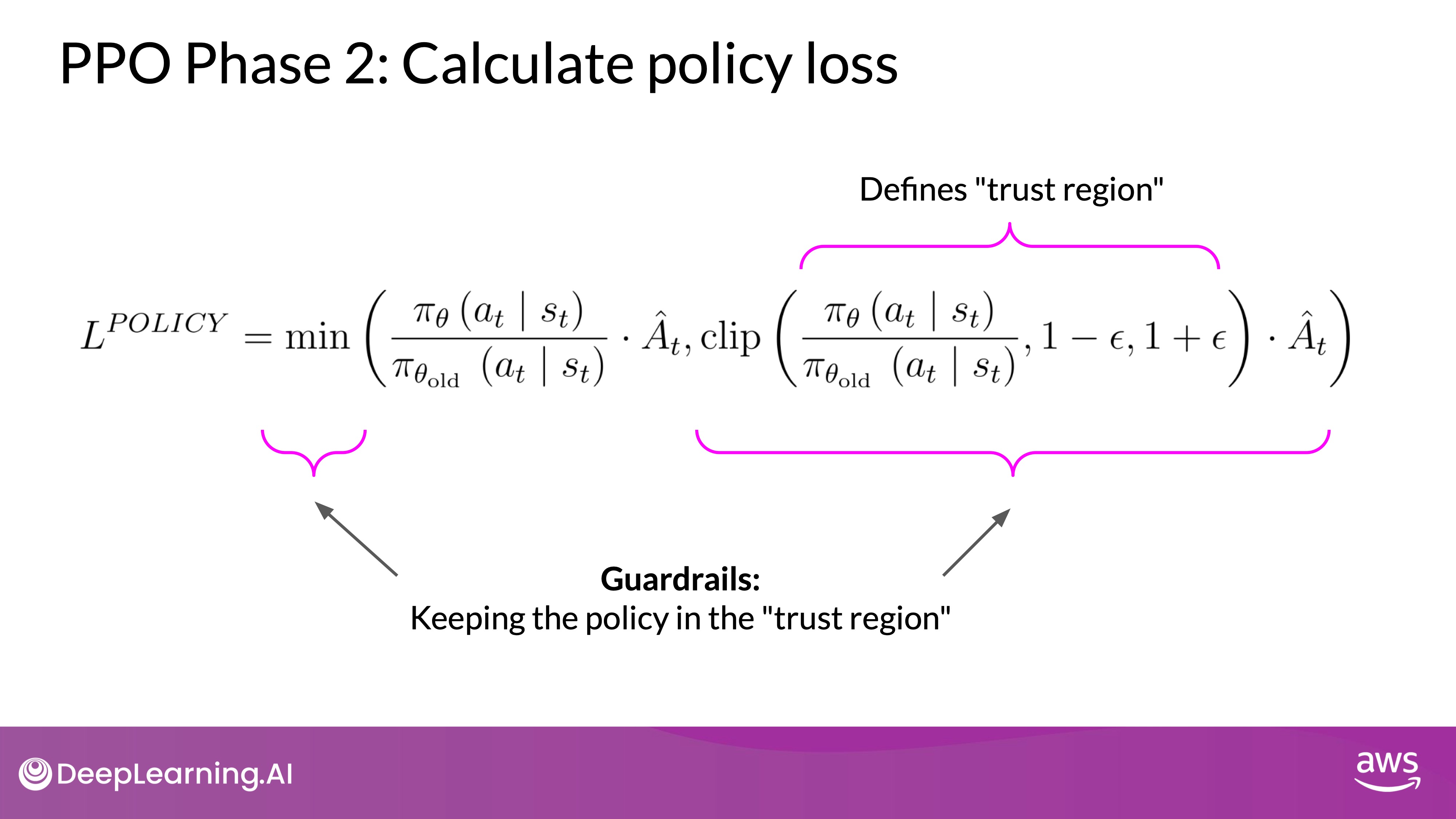
When optimizing the policy in Proximal Policy Optimization (PPO), directly maximizing the advantage term can lead to problems. This is because the calculations are only reliable if the advantage estimations are valid, which happens when the old and new policies are close to each other. Here’s how the trust region helps:
- Validity of Advantage Estimates:
- The advantage estimates are accurate only if the changes from the old policy to the new policy are small.
- Large changes can make the estimates unreliable.
- Guardrails for Optimization:
- To address this, PPO introduces a mechanism where it picks the smaller value between two terms: the original advantage term and a modified version.
- The modified version ensures that the updates keep the new policy close to the old one.
- Defining the Trust Region:
- This region, where the old and new policies are near each other, is called the trust region.
- The trust region acts as guardrails, preventing the model from making large, unstable updates.
- Ensuring Stability:
- These extra terms in the optimization function ensure that the updates to the policy remain within this trust region.
- By staying within the trust region, the updates are more likely to be reliable and effective.
Entropy Loss

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Entropy loss is an important concept in training Large Language Models (LLMs) using Proximal Policy Optimization (PPO). Let's break it down step by step to make it easier to understand:
- Policy Loss vs. Entropy Loss:
- Policy Loss: This part of the training process helps the model align with desired goals, like being helpful, honest, and harmless. It guides the model towards producing more accurate and preferred completions.
- Entropy Loss: Unlike policy loss, entropy loss focuses on maintaining the model's creativity and variability in its responses.
- Why Entropy is Important:
- If the entropy is kept low, the model might become too deterministic, meaning it could always respond in the same way to similar prompts. This lack of diversity can make the model predictable and less useful.
- High entropy, on the other hand, encourages the model to explore different responses, thereby maintaining creativity and avoiding repetitive outputs.
- Analogy with Temperature Setting:
- The concept of entropy in training is similar to the temperature setting in LLM inference (the stage where the model generates responses).
- Temperature Setting: Influences creativity during inference (response generation) by controlling how random or deterministic the output is.
- Entropy: Influences creativity during training by encouraging diverse responses.
Policy Objective and Advantage Term
PPO Objective
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Putting all terms together as a weighted sum, we get our PPO objective, which updates the model towards human preference in a stable manner. This is the overall PPO objective. The C1 and C2 coefficients are hyperparameters. The PPO objective updates the model weights through back propagation over several steps. Once the model weights are updated, PPO starts a new cycle. For the next iteration, the LLM is replaced with the updated LLM, and a new PPO cycle starts. After many iterations, you arrive at the human-aligned LLM.
Overall Process
The PPO algorithm iterates through cycles of experimentation and updates:
- Generate responses: The LLM generates responses to prompts.
- Evaluate and reward: The reward model assesses these responses and assigns rewards.
- Update weights: The PPO algorithm updates the LLM's weights based on the rewards, keeping the changes within the trust region.
- Repeat: This cycle continues until the model achieves the desired level of alignment with human values.
While PPO is the most popular method for RLHF because it has the right balance of complexity and performance. Other techniques like Q-learning are also used. Recent research, such as Stanford's direct preference optimization, offers simpler alternatives, indicating ongoing advancements in this field.