LLM-powered applications
Model optimizations for deployment
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Transitioning from adapting and aligning large language models (LLMs) to integrating them into applications involves several key considerations:
- Deployment Considerations:
- Inference Speed: Assess how fast the model needs to generate completions.
- Compute Budget: Determine the available compute resources.
- Trade-offs: Evaluate the willingness to compromise model performance for improved inference speed or lower storage requirements.
- Resource Requirements:
- External Interactions: Decide if the model needs to interact with external data or applications.
- Connection Methods: Plan how to connect the model to required resources.
- Consumption Methods:
- Application Interface: Define the intended application or API interface for model consumption.
Optimizing Models for Deployment
To ensure efficient deployment, consider optimizing the model using various techniques:
- Inference Challenges:
- Compute and Storage Requirements: Managing the resources needed for inference.
- Latency: Ensuring low latency for applications, critical for both on-premises and cloud deployments, and especially for edge devices.
- Size Reduction:
- Model Loading: Smaller models load faster, reducing inference latency.
- Performance Trade-offs: Balancing model size reduction with maintaining performance.
Model Optimization Techniques
There are three primary techniques for model optimization:
- Distillation
- Quantization
- Pruning
Distillation
- Teacher-Student Model: Use a larger model to train a smaller model, then use the smaller model for inference(production) to lower storage and compute budget.
- Knowledge Distillation: Minimize the distillation loss between the teacher and student model using a probability distribution over tokens.
- Temperature Parameter: Increase the creativity of the language generated by the teacher model by adjusting the softmax function's temperature.
Details
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Steps in Model Distillation
1. Preparing the Teacher and Student Models
- Teacher Model: Begin with a fine-tuned, larger LLM that serves as the teacher model. This model is already trained on your data and performs well in generating accurate predictions.
- Student Model: Create a smaller LLM that will act as the student model. This model is initialized and will learn to mimic the teacher model’s behavior.
2. Generating Training Data
- Freezing Teacher Model Weights: The weights of the teacher model are frozen to ensure that its performance remains consistent throughout the distillation process.
- Generating Completions: Use the teacher model to generate outputs (completions) for your training data. These outputs include probability distributions over possible tokens.
3. Calculating Distillation Loss
- Softmax Layer and Probability Distribution: The teacher model’s softmax layer produces a probability distribution over tokens. This distribution is referred to as soft labels.
- Temperature Parameter: Apply a temperature parameter to the softmax function to smooth the probability distribution. A higher temperature value broadens the distribution, making it less peaked.
- High Temperature: Increases the diversity of token probabilities, providing richer information for the student model to learn from.
- Distillation Loss Calculation: Compare the student model's predicted probability distribution to the soft labels from the teacher model. This loss, called the distillation loss, is calculated by minimizing the difference between these distributions.
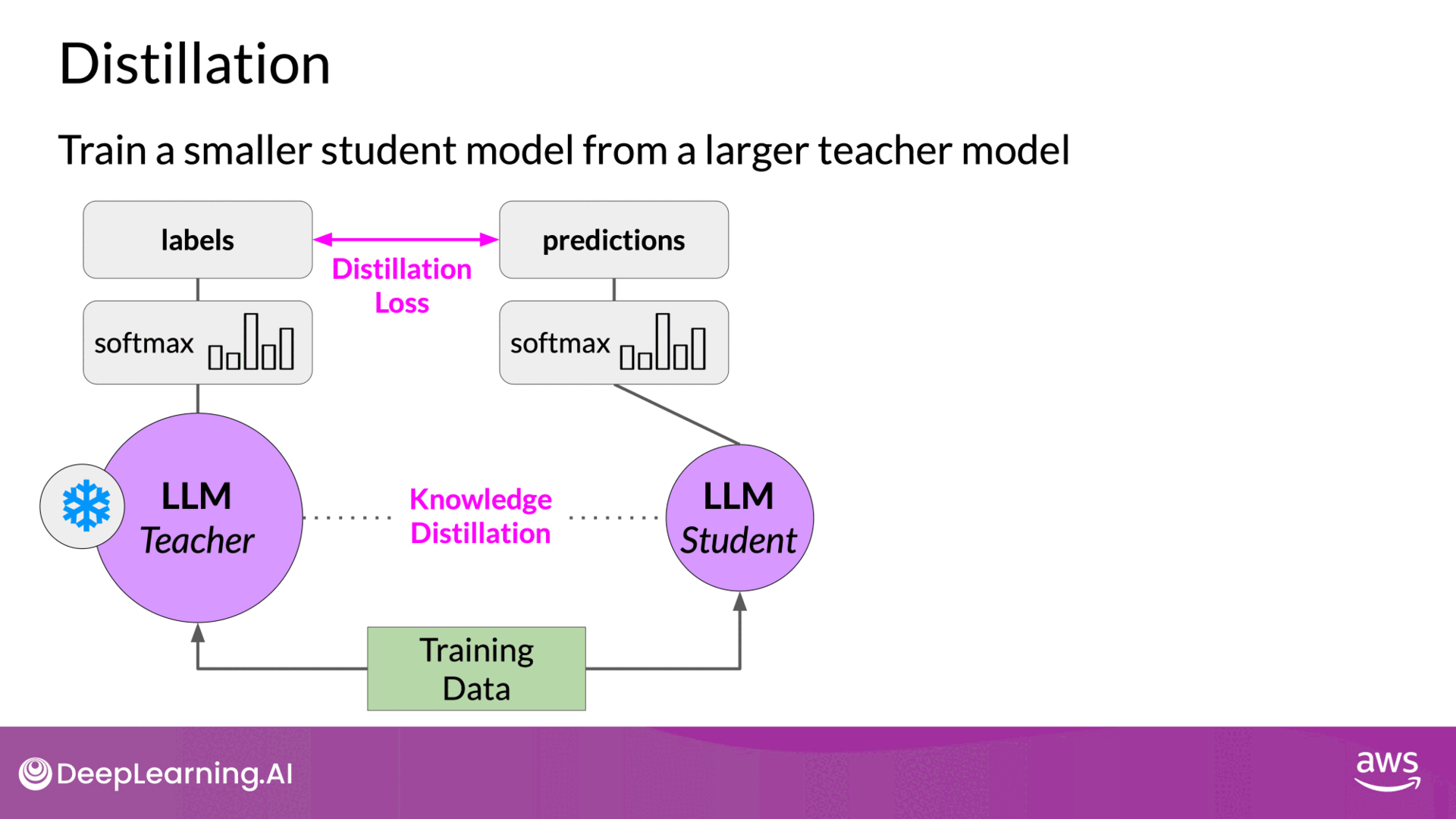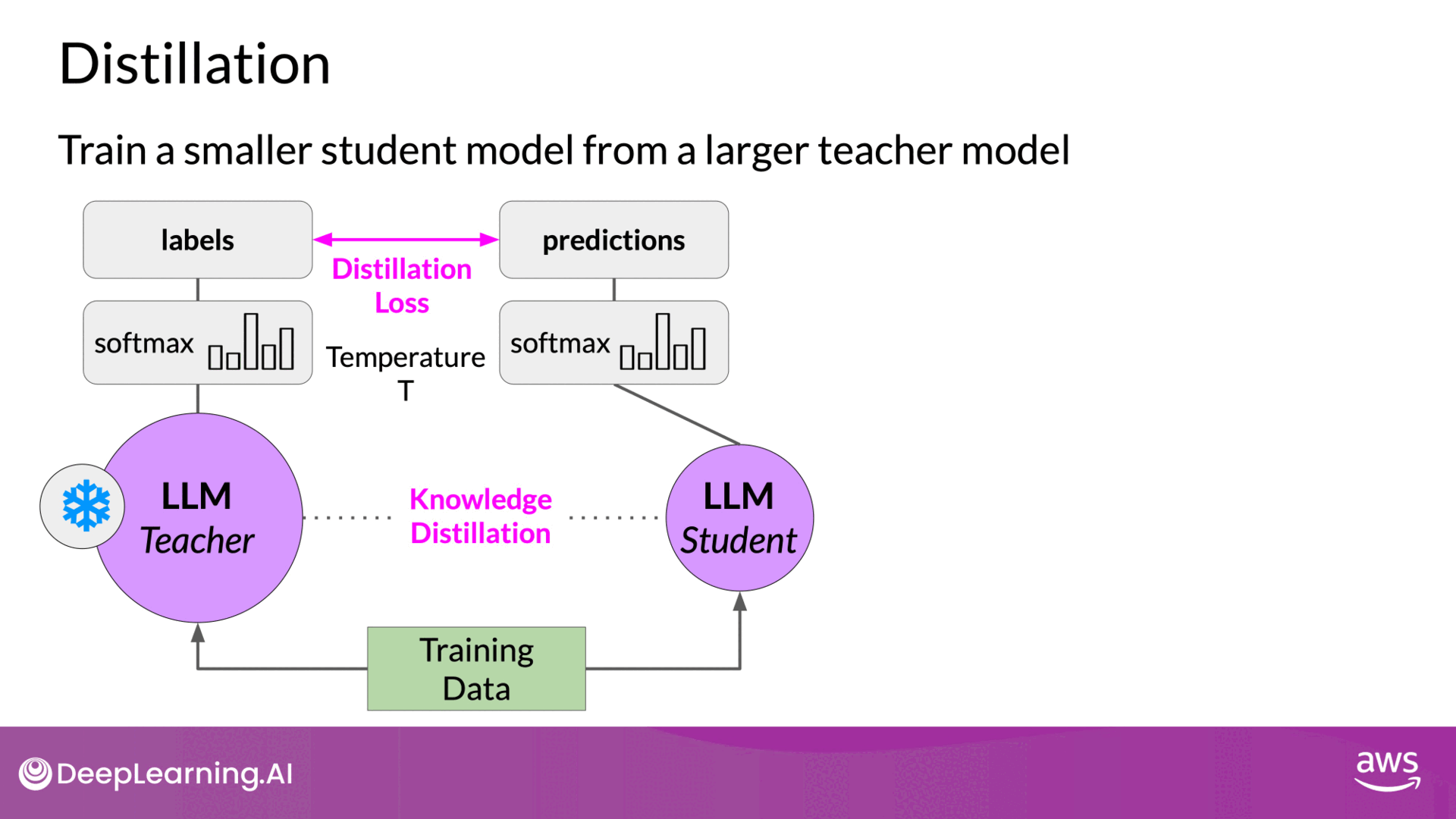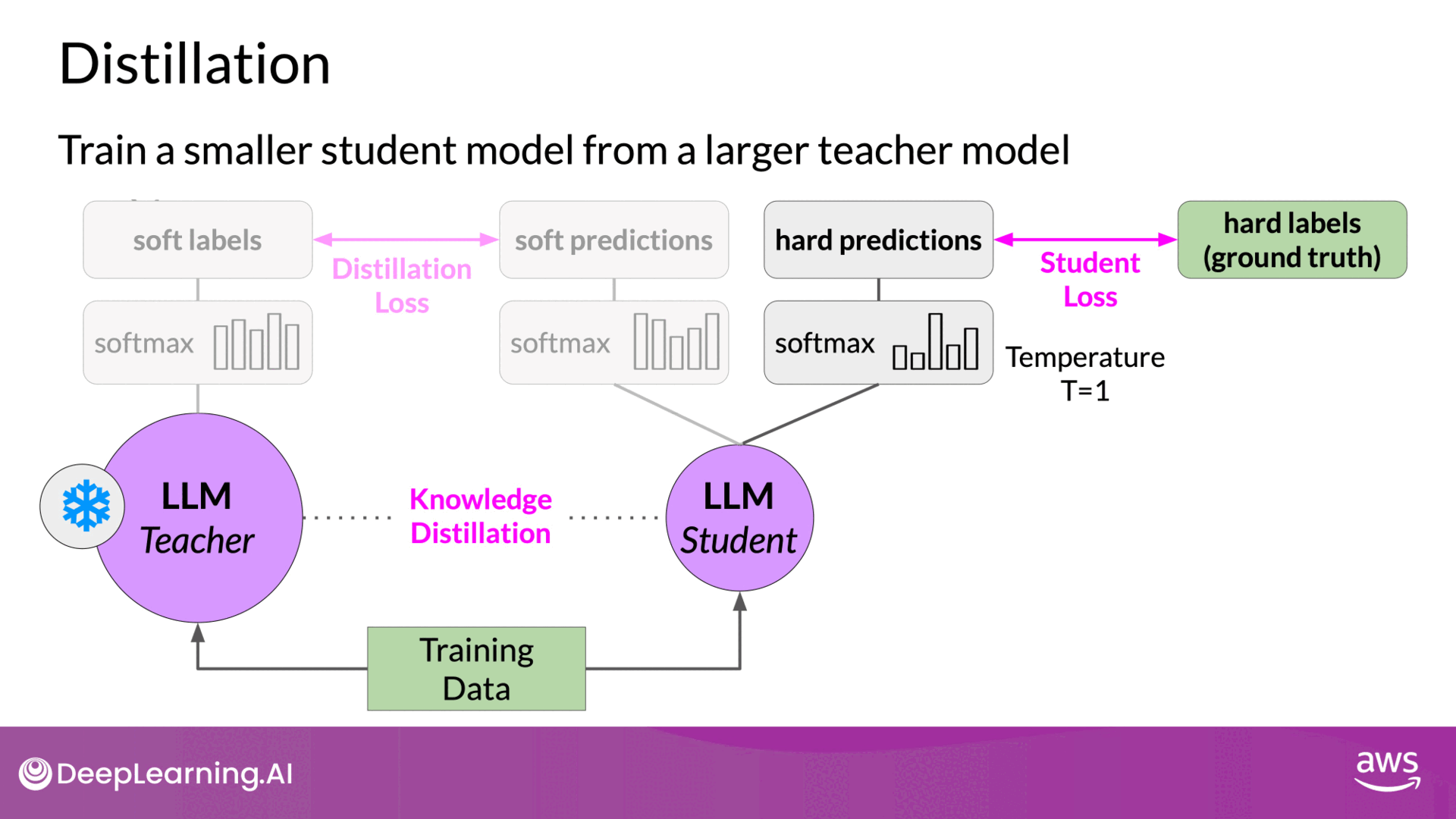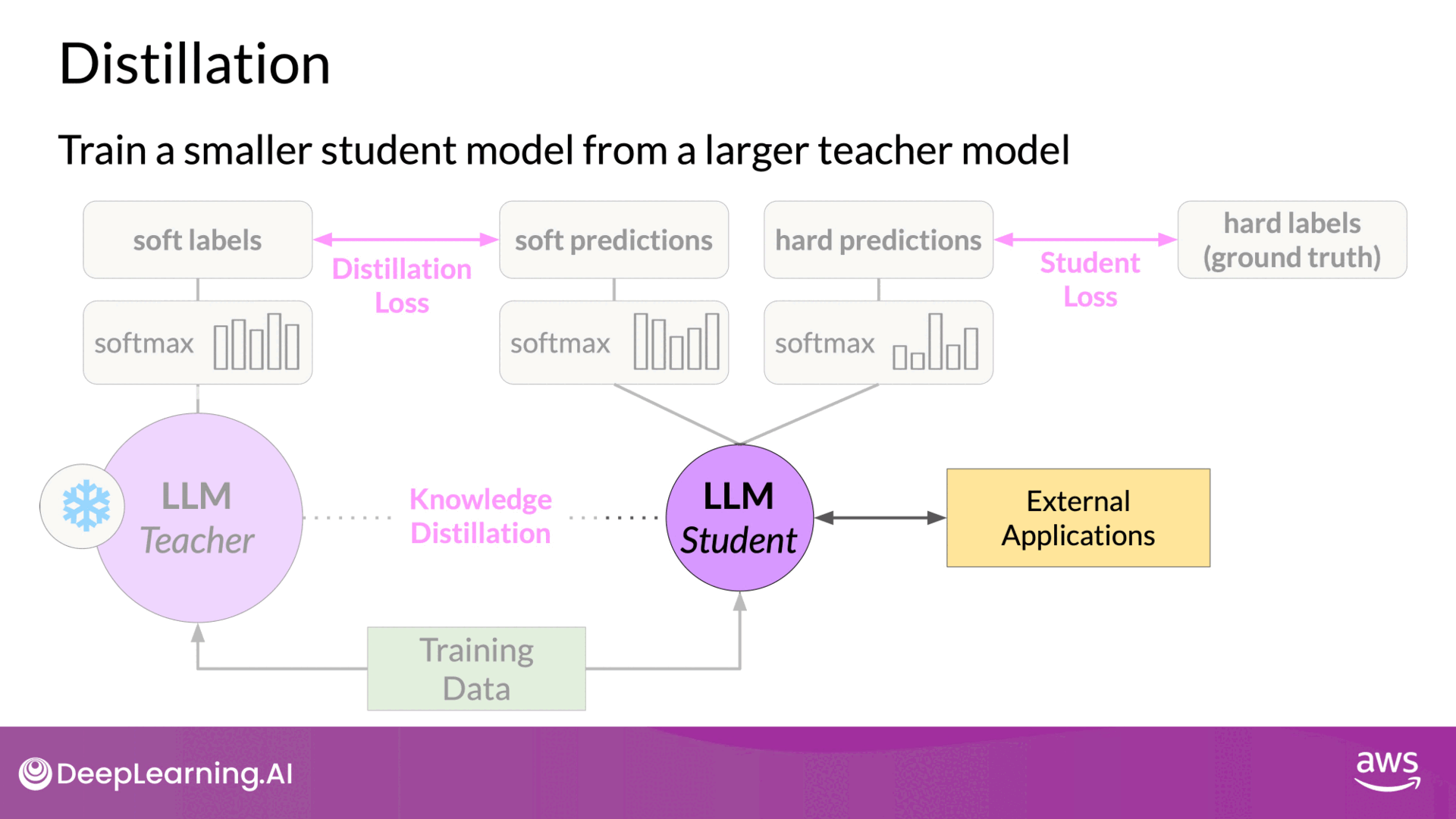
4. Training the Student Model
- Generating Student Model Completions: Simultaneously, use the student model to generate completions for the same training data.
- Standard Softmax Function: The student model uses the standard softmax function without varying the temperature setting to generate its predictions.
- Student Loss Calculation: The student model's predictions, referred to as hard predictions, are compared to the ground truth labels. This loss is called the student loss.
- Combining Losses: The total loss for training the student model is a combination of the distillation loss and the student loss. This combined loss is used to update the weights of the student model through backpropagation.
- Updating Weights: Gradients from both losses are used to adjust the weights, ensuring the student model learns from both the teacher’s soft labels and the actual ground truth labels.
5. Deploying the Student Model
- Inference with Student Model: Once training is complete, the smaller student model is used for inference. This model retains much of the performance of the larger teacher model but is more efficient in terms of computational resources and inference speed.
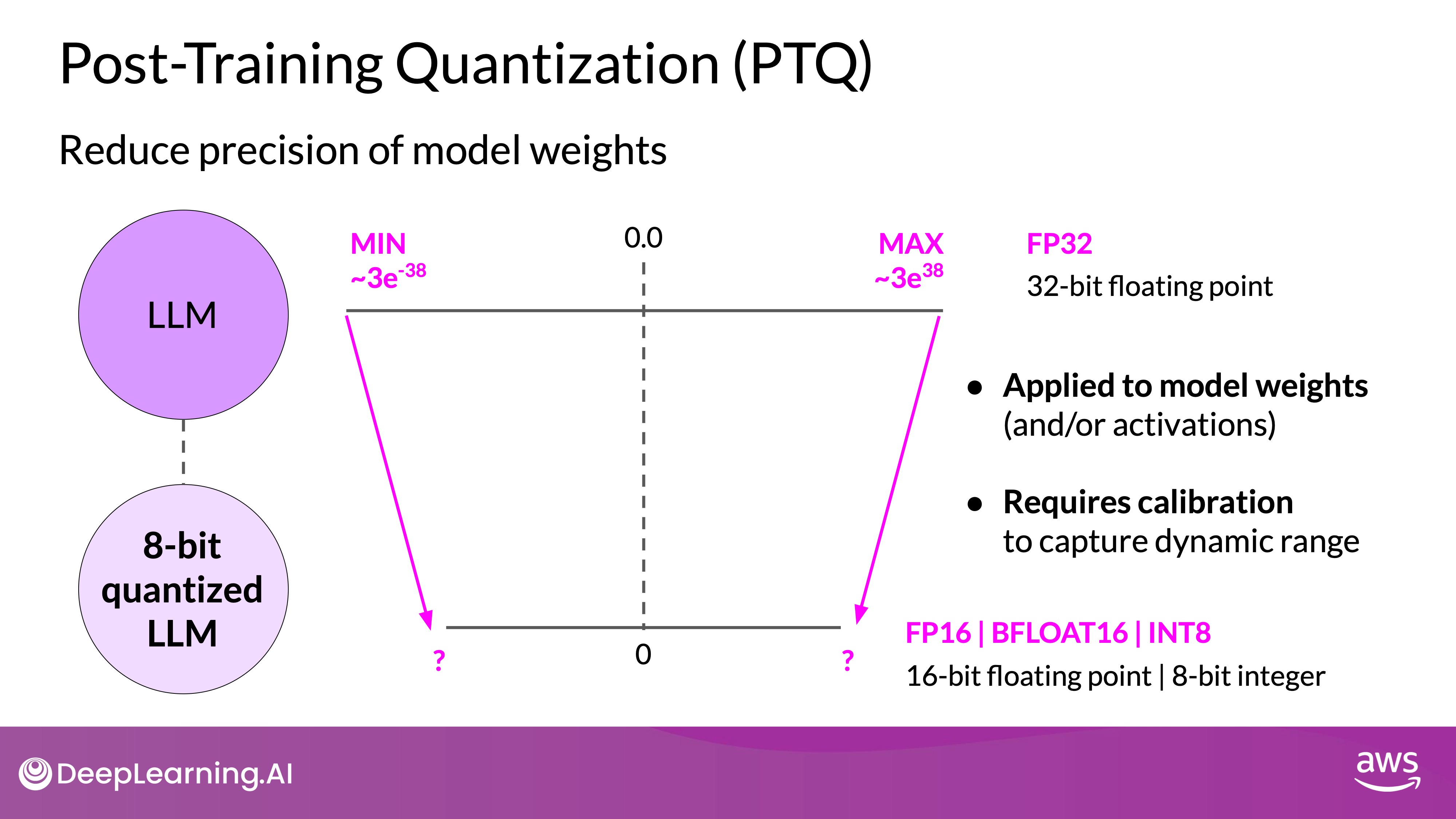
Quantization
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Post Training Quantization (PTQ): Transform a model's weights to a lower precision representation, reducing model size and memory footprint.
- Precision Levels: Use 16-bit floating point or 8-bit integer representations.
- Calibration Step: Statistically capture the dynamic range of parameter values for effective quantization.
QAT: Quantization is integrated into the training process, leading to better performance under quantization but requiring more complex training.
PTQ: Quantization is applied after training, offering ease of implementation but potentially with a small trade-off in performance.
As with other methods, there are tradeoffs because sometimes quantization results in a small percentage reduction in model evaluation metrics. However, that reduction can often be worth the cost savings and performance gains.
Pruning
- Eliminate Redundant Weights: Remove weights that do not significantly contribute to model performance. These are the weights with values very close to or equal to zero
- Retraining: Some methods require full model retraining, while others focus on parameter-efficient fine-tuning such as
LoRA. - Impact on Size and Performance: The actual impact on model size and performance may vary.
Benefits of Optimization Techniques
Each technique aims to improve model performance during inference without significantly impacting accuracy:
- Distillation: Effective for reducing the redundancy for encoder-only models such as
Burtwhich has a lot of representation redundancy. Note that with Distillation, you're training a second, smaller model to use during inference. You aren't reducing the model size of the initial LLM in any way. - Quantization: Offers substantial cost savings and performance gains despite minor reductions in model evaluation metrics.
- Pruning: Focuses on reducing model size by eliminating less impactful weights, with varied practical impact.
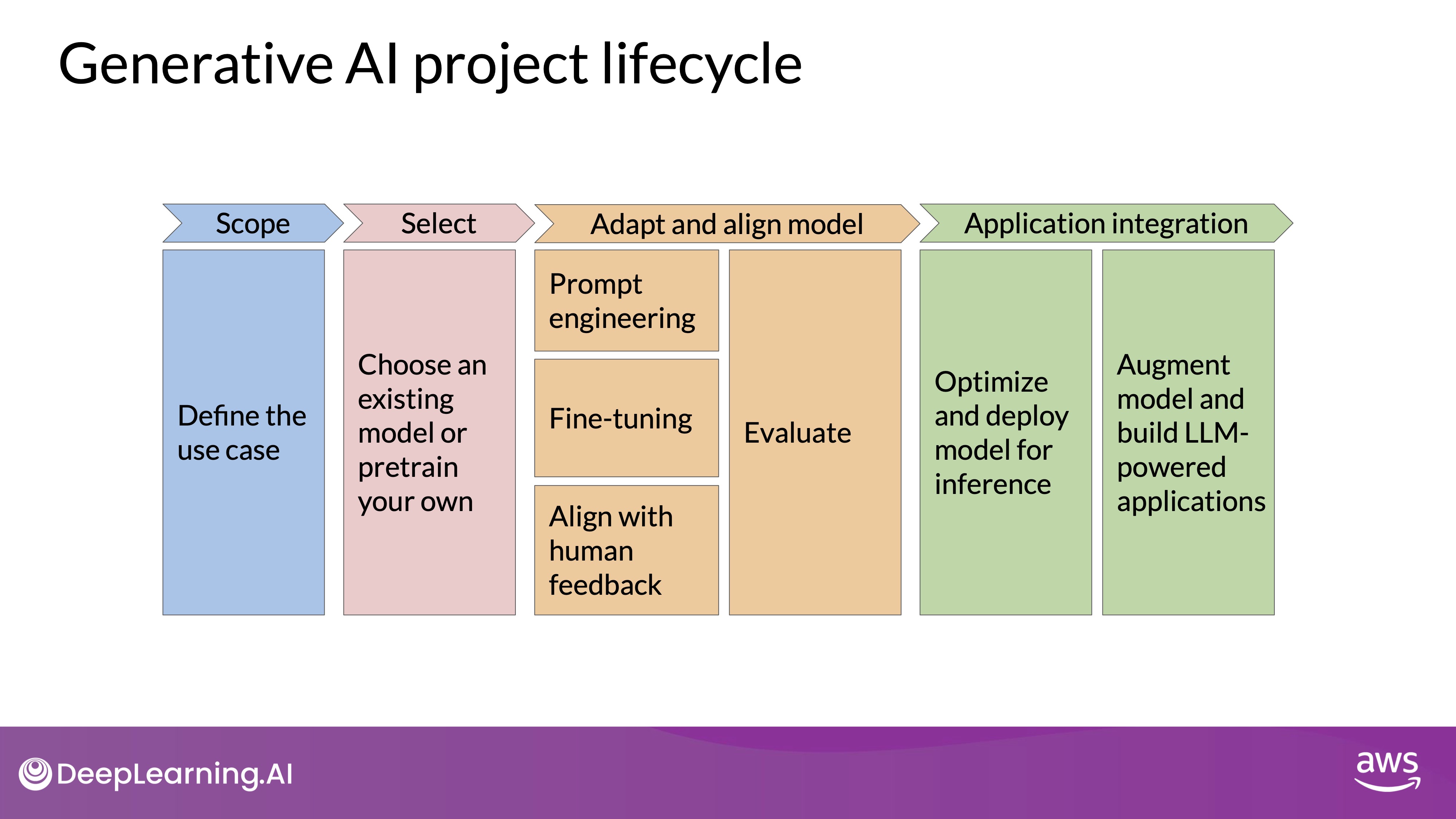
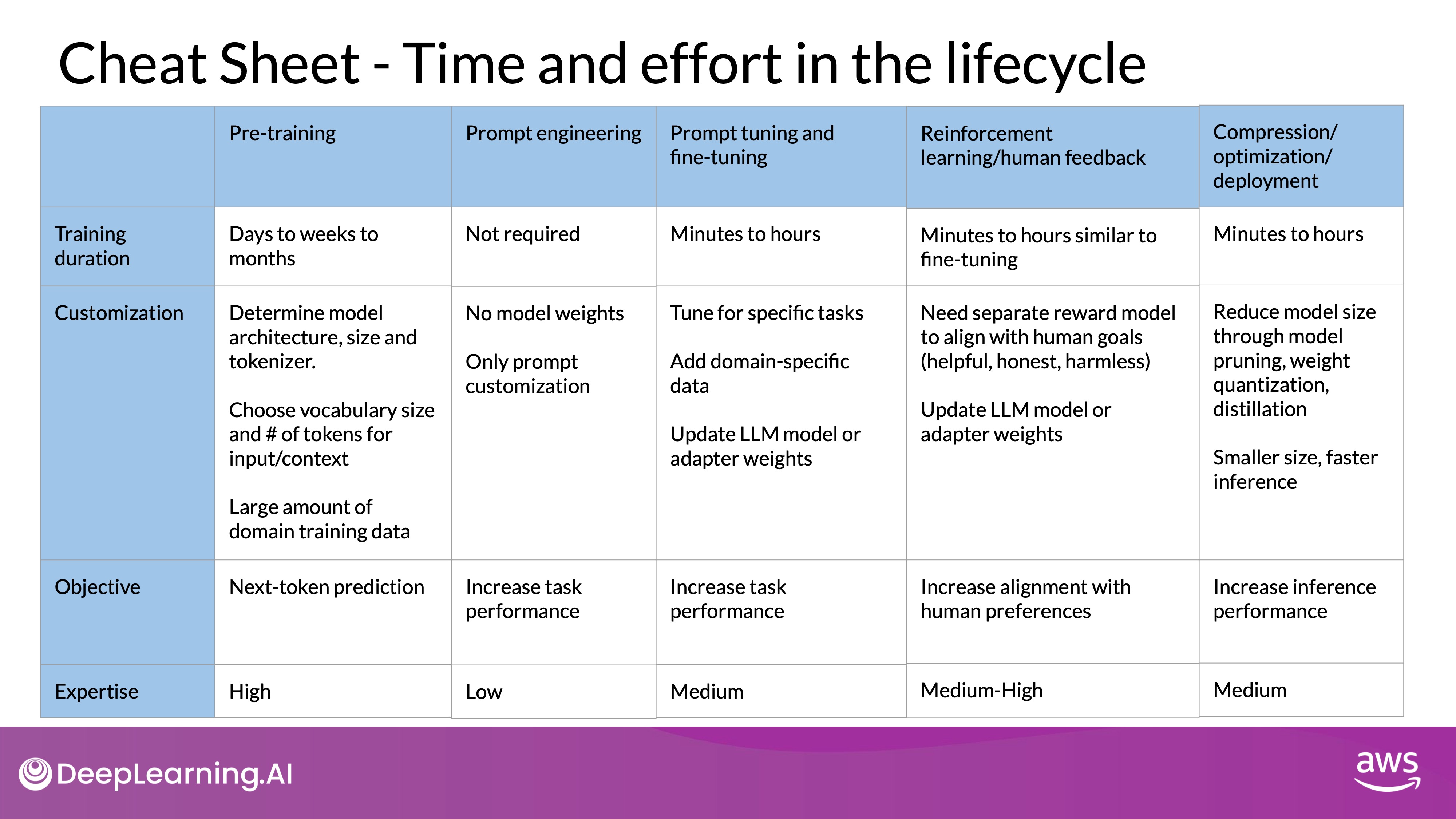
Generative AI Project Life Cycle
This section outlines the stages of developing a generative AI application, from model selection to deployment. Understanding these phases helps in planning the time and effort required for each step.
- Pre-training and Model Selection Pre-training a large language model (LLM) is highly complex, involving decisions about model architecture, large datasets, and specialized expertise. This stage requires significant effort and resources.
Most development starts with an existing foundation model, allowing you to skip the pre-training phase. This foundation provides a robust base, reducing the initial workload.
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Performance Assessment and Fine-Tuning
- Prompt Engineering:
- Initial Assessment: Evaluate the model’s performance through prompt engineering, which involves crafting and refining prompts to elicit desired responses. This stage requires minimal technical expertise and no additional training.
- Adjustments: If the model's performance is inadequate, proceed to prompt tuning and fine-tuning.
- Fine-Tuning:
- Methods: Depending on the use case and goals, choose between full fine-tuning or parameter-efficient techniques like LoRA or prompt tuning.
- Technical Requirements: Fine-tuning demands some technical skills but can be efficient with a small training dataset, potentially completing in a day.
- Prompt Engineering:
- Model Alignment with Human Feedback(RLHF):
- Using Existing Reward Models: This process can be quick if an existing reward model is available, as demonstrated in the lab exercises.
- Training New Reward Models: If a new reward model is needed, the process can be time-consuming due to the effort in collecting human feedback.
- Optimization Techniques:
- Complexity and Effort: Optimization techniques fall in the middle regarding complexity and effort. They can be implemented quickly if the changes do not significantly impact performance.
- Techniques: These include methods such as distillation, quantization, and pruning to enhance model efficiency and deployment readiness.
- Final Steps and Deployment:
- Training and Tuning Completion: After completing all the steps, you should have a well-tuned LLM optimized for your specific use case and ready for deployment.
- Addressing Remaining Issues: The final videos in the course will cover potential performance problems that may arise before launching your application and the techniques to overcome them.
By following these stages, you can systematically develop and deploy a generative AI application, ensuring it meets performance and optimization goals.
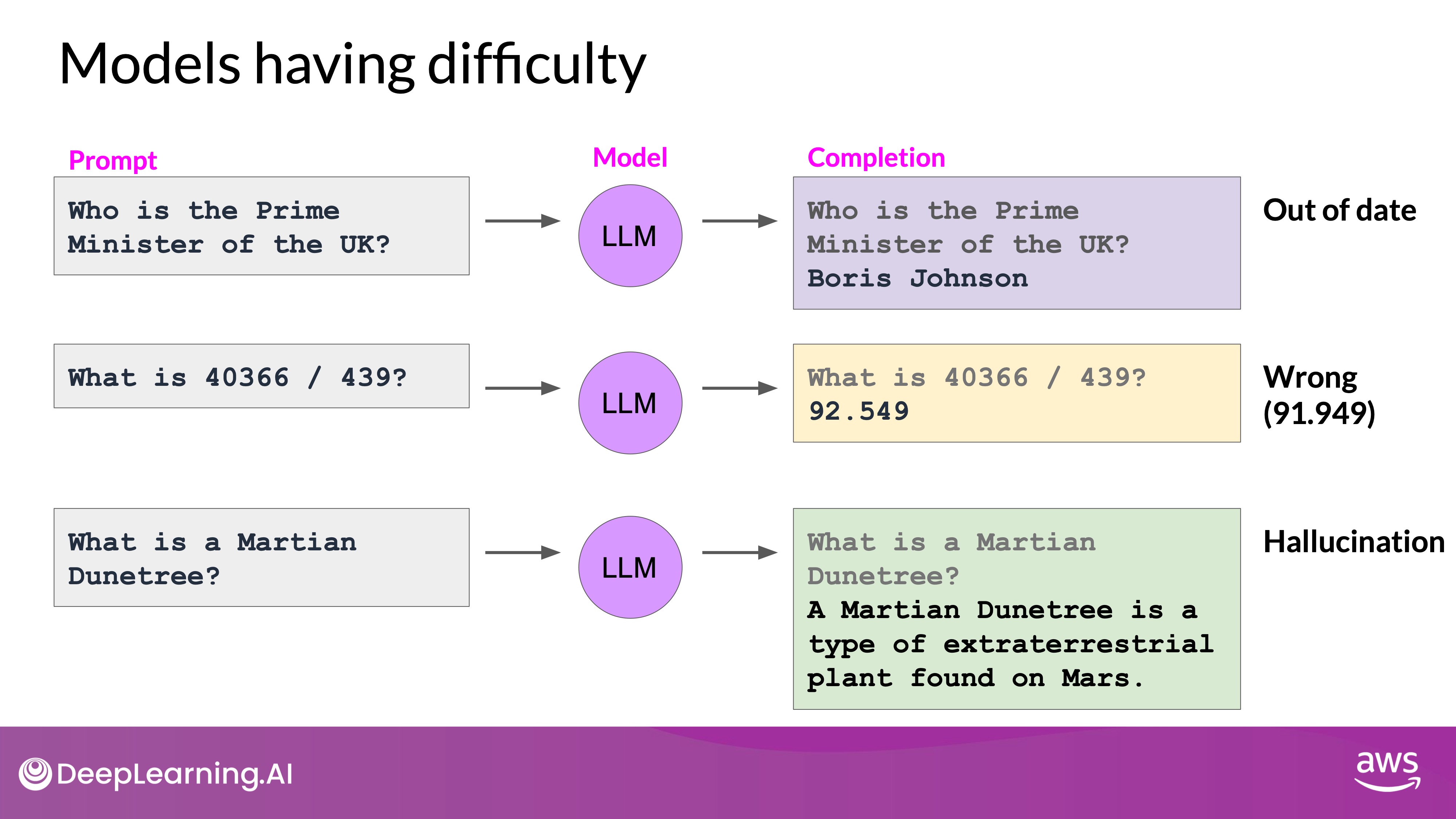
Challenges Beyond Training
Training, tuning, and aligning techniques help build effective models, but some broader issues persist with large language models (LLMs) that cannot be solved by training alone. Here are some key challenges:
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Knowledge Cutoff
- Outdated Information: LLMs are limited to knowledge available up to their last training update. For example, a model trained in early 2022 may incorrectly identify Boris Johnson as the current British Prime Minister, unaware of his departure in late 2022.
- Solution: Connecting LLMs to external, up-to-date data sources can address this issue, allowing models to access and incorporate the latest information during inference.
Mathematical Limitations
- Complex Calculations: LLMs struggle with precise mathematical operations, such as division. They predict the next best token based on training data rather than performing actual calculations, leading to potential errors.
- Solution: Enhancing models with external computation tools or APIs can improve accuracy for tasks requiring precise calculations.
Hallucinations
- Inventing Information: LLMs often generate plausible-sounding text even when they lack the correct information. This tendency to hallucinate can lead to incorrect or fictional responses.
- Solution: Integrating external validation sources and implementing techniques like Retrieval Augmented Generation (RAG) helps reduce hallucinations by grounding responses in real data.
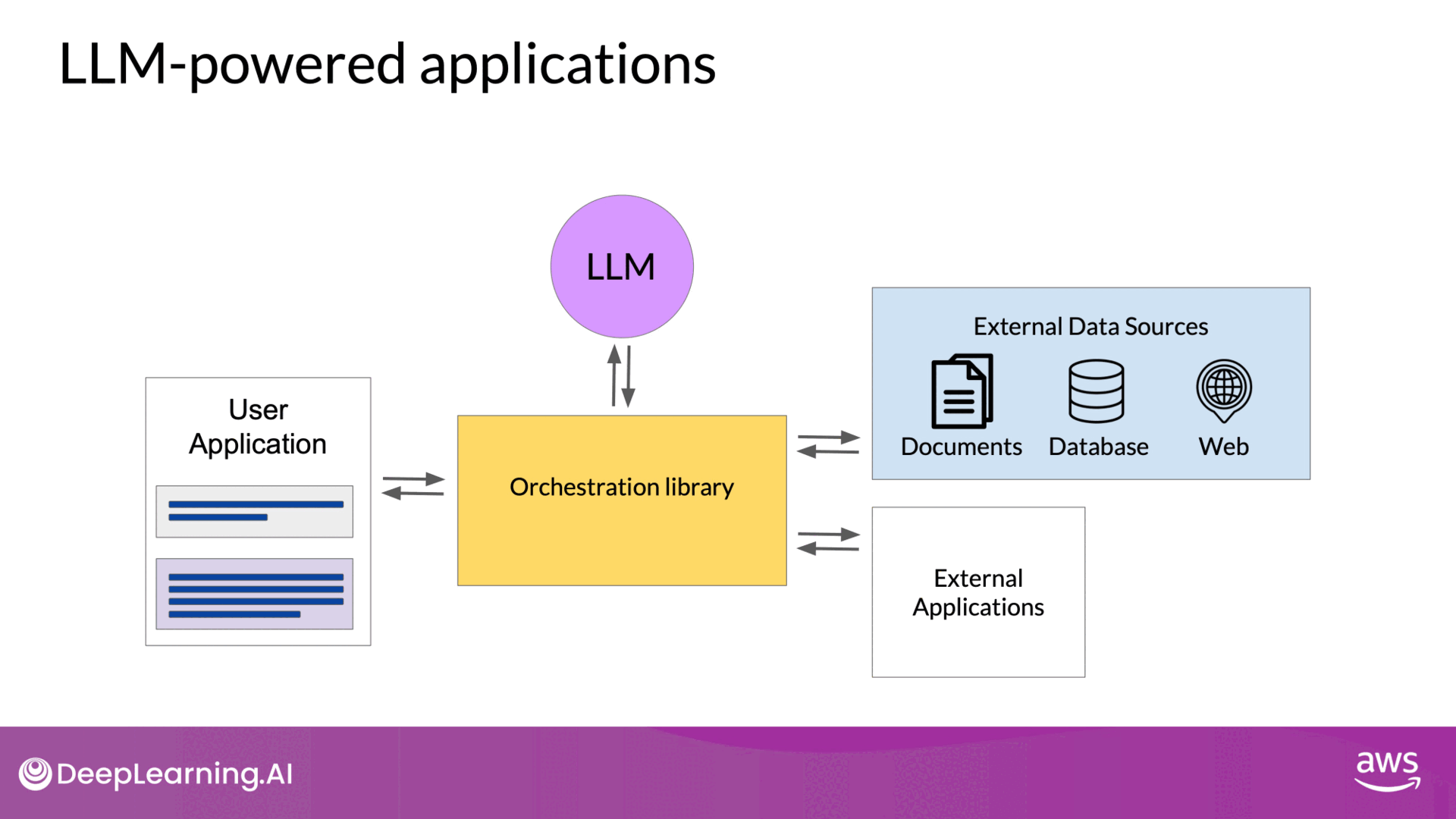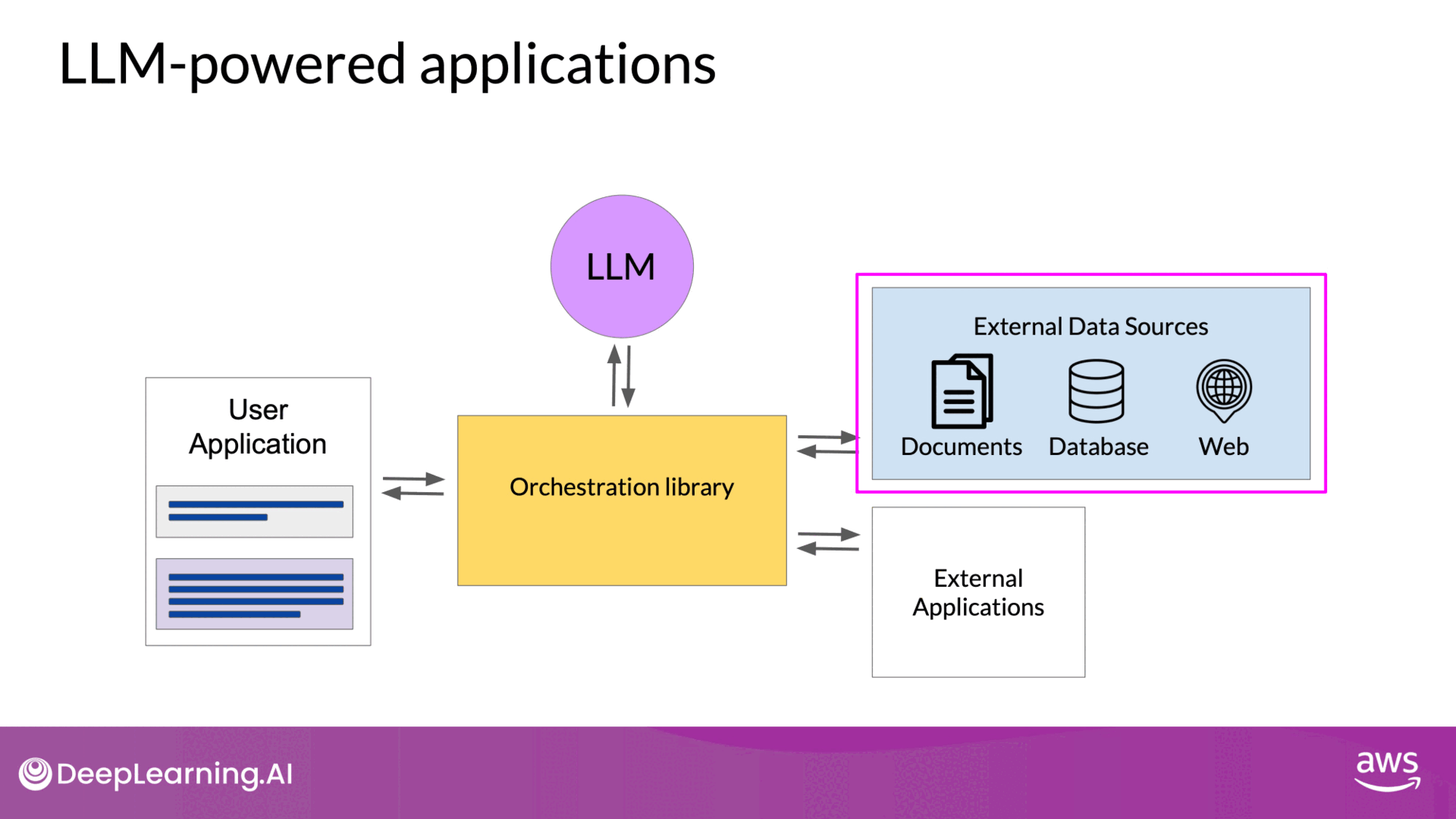
Connecting LLMs to External Data Sources
TL;DR - By connecting LLMs to external data sources and applications, you can address limitations such as outdated knowledge, mathematical inaccuracies, and hallucinations. It enables the model to incorporate information it did not see during training when generating text. Techniques like RAG significantly enhance the utility and reliability of LLMs, enhancing their performance by providing up-to-date and accurate information.
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
RAG connects LLMs to external data sources(Documents, Wikis Expert Systems, Web pages, Databases, Vector Store) to supplement the model's internal knowledge. This approach is more cost-effective and flexible than frequent retraining.
- User Input and Query Encoding
- User Query: The user provides an input prompt or query, such as asking for information about a specific legal case.
- Query Encoder: The query is passed to the query encoder, which encodes the input into a form suitable for searching external data sources. This encoding aligns with the format of the stored external data.
- Retrieving Relevant Data
- External Data Source: The encoded query is used to search an external data source. This could be a vector store, SQL database, CSV files, or another data format.
- Finding Relevant Documents: The retriever component identifies the most relevant documents or data entries from the external source based on the encoded query.
- Returning Documents: The retriever returns the best matching document or a group of documents that are most relevant to the input query.
- Combining Data with User Query
- Expanding the Prompt: The retrieved documents are combined with the original user query to form an expanded prompt. This expanded prompt now includes additional information from the external data source.
- Passing to LLM: The expanded prompt is then passed to the large language model (LLM).
- Generating Completion: The LLM uses the combined information from the original query and the retrieved data to generate a more accurate and relevant response.
- Overcoming Knowledge Cutoffs: By accessing real-time data, RAG allows LLMs to provide accurate, up-to-date information.
- Reducing Hallucinations: Grounding responses in external data sources minimizes the risk of generating incorrect or fictional information.
- Enhanced Utility: Integrating multiple types of data sources (e.g., private databases, internet, vector stores) improves the model's relevance and accuracy for various use cases.
Legal Research(Example)

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- User Query: The lawyer inputs a query asking about the plaintiff in a specific legal case number.
- Query Encoding: The input query is encoded by the query encoder to match the format of the external legal documents.
- Retrieving Data:
- The encoded query searches the corpus of past court filings.
- The retriever identifies and returns a document containing information about the specific case number.
- Combining Data:
- The retrieved court filing document is combined with the original user query.
- This expanded prompt, containing both the query and relevant legal document, is passed to the LLM.
- Generating Completion: The LLM processes the expanded prompt and generates a response that accurately answers the lawyer's question about the plaintiff, based on the retrieved legal document.
Implementing RAG
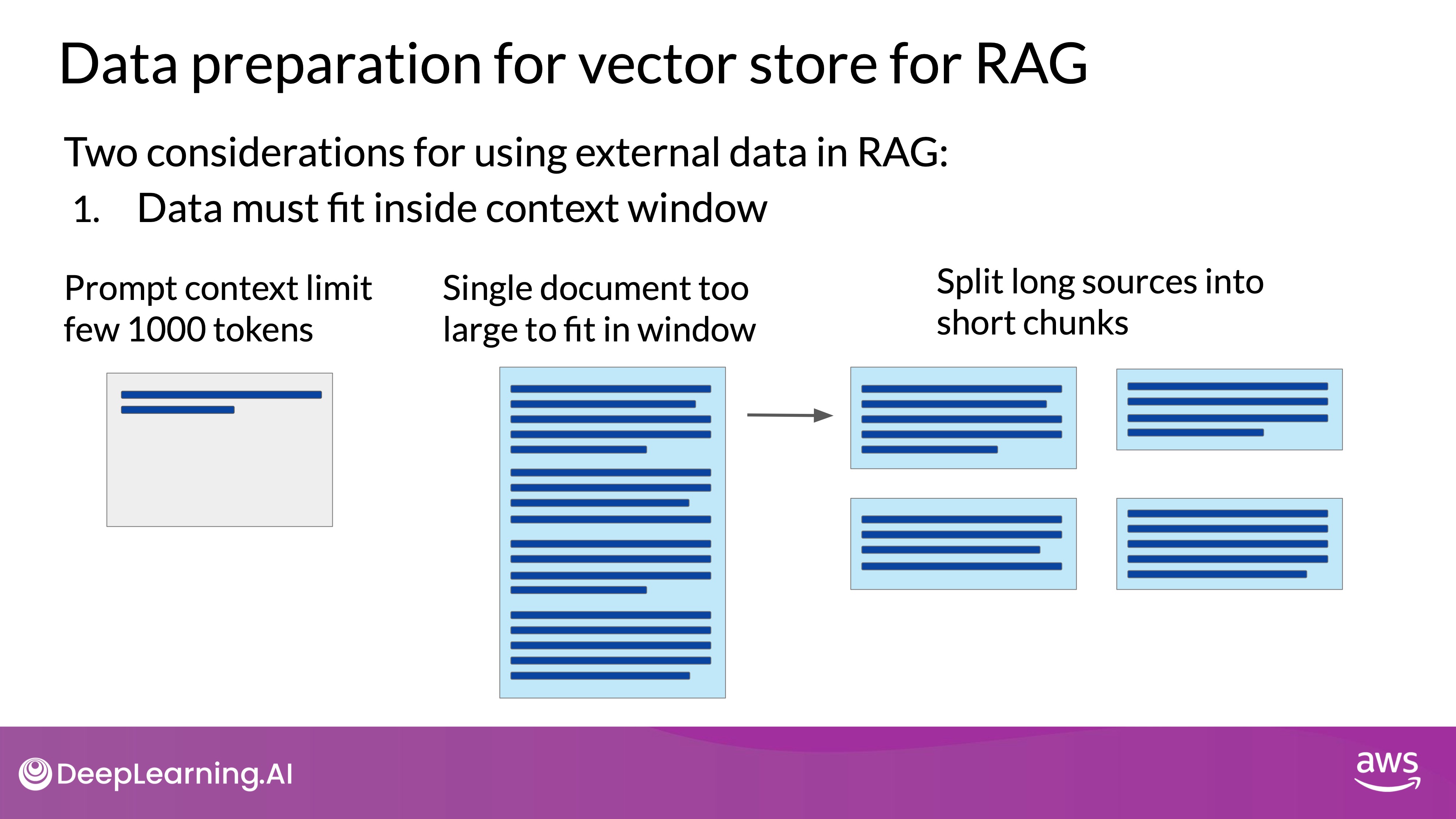
Data Must Fit Inside the Context Window
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Context Window Limitations: LLMs have a limited context window, typically only a few thousand tokens. This means that the entire external data source cannot be processed at once.
- Splitting Data: External data must be split into smaller, manageable chunks that fit within the context window. This is crucial for ensuring that the LLM can process the data effectively.
- Tools for Chunking: Libraries such as
Langchaincan automate the process of chunking external data into appropriate sizes, ensuring that each chunk is small enough to be handled by the LLM.
Data Must Be in a Format That Allows Its Relevance to Be Assessed at Inference Time: Embedding Vectors

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Vector Representations: Instead of storing raw text, data is stored as vector representations. Rag methods take the small chunks of external data and process them through the
LLM, to create embedding vectors for each. These new representations of the data can be stored in structures calledvector stores, which allow for fast searching of datasets and efficient identification of semantically related text. - Similarity-Based Search:
Vector storesenable efficient search based on similarity measures such as cosine similarity. This allows the retriever to quickly find and return the most relevant data chunks. - Data Structure: Vector databases, a specific implementation of vector stores, not only store vectors but also associate each vector with a key. This allows the system to return not just the relevant data but also citations or references to the original sources.
Using an LLM to create the vector library ensures that the vector representations of the text capture the rich semantic information necessary for effective retrieval in a RAG system.
The LLM-generated vectors align closely with how the LLM will process queries during inference, leading to more accurate and relevant search results. Simply using a tokenizer would not provide the depth of understanding or the consistency needed for this task.
Semantic relationships refer to the connections between words or phrases based on their meanings rather than just their surface-level features, such as spelling or syntax. In the context of language models and embeddings, this concept is crucial for understanding how words are related to each other in terms of meaning.
While you can use basic tokenization techniques like one-hot encoding, the performance of your data retrieval system will suffer significantly. This is because one-hot encoding does not capture the semantic relationships between words, which are crucial for effective and accurate information retrieval. For better performance, you should use embeddings generated by LLMs or other sophisticated models that are designed to capture the meaning and context of text.
Integrating LLMs with External Applications
In the above section, we explored how LLMs can interact with external datasource, but LLMs can be augmented to handle complex tasks that require interacting with databases, APIs, and other external systems. We'll use an example of a customer service bot to demonstrate how LLMs can be augmented to handle complex tasks to extend LLM utility beyond language tasks, such as:
- Triggering Actions via APIs: By connecting to external applications, LLMs can initiate actions in the real world. For example, ShopBot can trigger API calls to generate shipping labels or query databases to retrieve order details.
- Integrating with Programming Resources:
- Python Interpreter: An LLM can connect to a Python interpreter, allowing it to perform accurate calculations or other programmatic tasks within its outputs.
- Generating Commands: LLMs can generate SQL queries, Python scripts, or other code snippets that external systems can execute, based on the user’s input and the model’s reasoning.
Example: Chatbot Handling a Return Request
- Customer Interaction:
- Return Request: The customer initiates a return process by indicating their desire to return a pair of jeans.
- Order Number Retrieval: ShopBot requests the order number from the customer. Once provided, it retrieves the order information from a transaction database.
- Data Retrieval - SQL Query for Order Information: ShopBot could use a Retrieval-Augmented Generation (RAG) system to query the backend order database via SQL, retrieving the relevant order details rather than extracting information from a document corpus.
- Processing the Return:
- Confirming Return Items: ShopBot asks if the customer wishes to return any additional items. After confirming the items, it proceeds to initiate the return process.
- Requesting a Shipping Label: ShopBot interacts with the company's shipping partner by using their Python API to request a shipping label. It gathers necessary details, such as the customer’s email, and includes this in the API request.
- Finalizing the Interaction - Emailing the Shipping Label: ShopBot sends the shipping label to the customer's email address and confirms the completion of the process with the customer, ending the conversation.
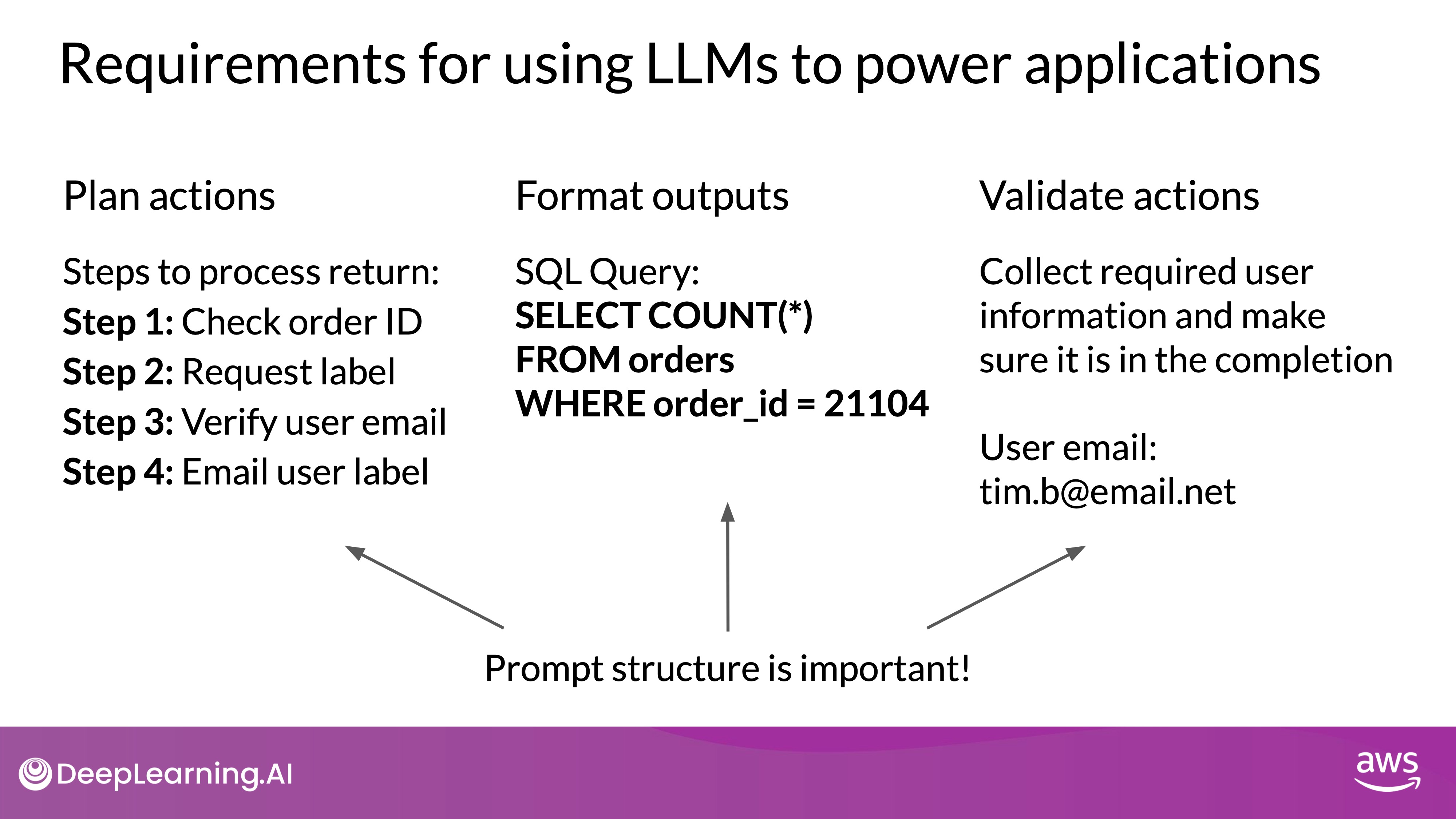
Key Requirements for LLM-Driven Applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Generating Actionable Instructions:
- Clarity and Specificity: The LLM must generate clear and specific instructions that the application can understand and execute. For example, in the above case, this includes steps like checking the order ID and requesting a shipping label.
- Correspondence to Allowed Actions: The instructions generated must align with the allowed actions of the external application.
- Impact on Output Quality: Properly structured prompts are crucial in ensuring that the LLM generates high-quality plans or instructions that adhere to the desired output format. This structuring directly influences the effectiveness of the LLM's interaction with external applications.
- Formatting the Output for Application Integration:
- Structured Output: The completion must be formatted correctly for the application to interpret it. This could range from specific sentence structures to more complex outputs like SQL queries or Python scripts.
- Example: A SQL query might be structured as:
SELECT * FROM orders WHERE order_id = '123456';
- Collecting and Validating Information:
- User Input Validation: The LLM must collect necessary information from the user, such as verifying the customer’s email address before sending the shipping label.
- Validation in Completion: The collected information should be validated and included in the LLM’s completion so that it can be passed to the external application, ensuring the actions taken are accurate and authorized.