Build a LLM application
The section is to bring together the various components and considerations necessary to build effective LLM-powered applications. The discussion emphasizes that creating end-to-end solutions involves more than just deploying large language models (LLMs); it requires a comprehensive infrastructure and strategic integration of multiple elements.
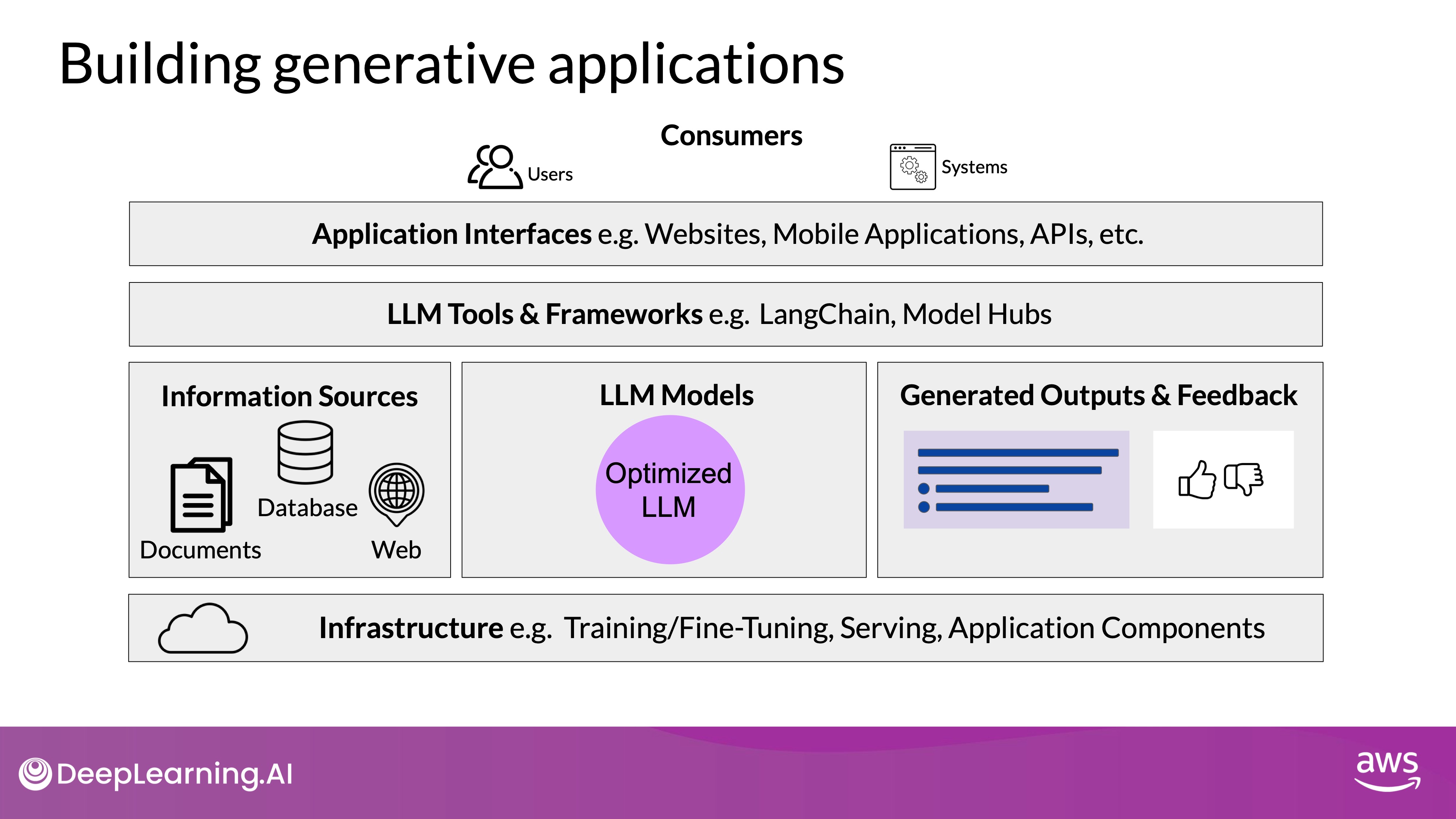
Key Components for LLM-Powered Applications
- Infrastructure Layer:
- Purpose: Provides the essential compute, storage, and network resources required to serve LLMs and host application components.
- Options: Can be implemented using on-premises infrastructure or through cloud services that offer on-demand and pay-as-you-go models.
- Considerations: Choose infrastructure based on your specific inference needs, such as whether real-time or near-real-time interaction with the model is required.
- Large Language Models:
- Model Deployment: Includes both foundation models and those adapted for specific tasks. These models are deployed on the infrastructure layer to facilitate inference.
- External Data Retrieval: May involve retrieving information from external sources, particularly in retrieval-augmented generation (RAG) scenarios.
- Model Output Handling: Depending on the application, it might be necessary to capture and store outputs, such as storing user completions during a session to supplement the LLM’s fixed context window size.
- Tools and Frameworks:
- Implementation Aids: Tools like LangChain provide built-in libraries to implement techniques like PAL, ReAct, or chain-of-thought prompting.
- Model Hubs: These allow for centralized management and sharing of models across applications, streamlining the development process.
- User Interface and Security:
- User Interface (UI): This is the layer where users or other systems interact with the application, typically through a website, REST API, or other interfaces.
- Security Components: Essential for safeguarding the application and ensuring secure interactions with users and external systems.
High-Level Architecture Stack
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Comprehensive View: The architecture stack highlights that the LLM is just one component in a broader system. The stack includes infrastructure, models, tools, and the user interface, all of which must be carefully integrated to create a robust generative AI application.
- User Interaction: Whether the users are human or other systems, they will interact with the entire architecture stack, making it crucial to consider how all components work together.
- Model Alignment with Human Preferences: Techniques like Reinforcement Learning with Human Feedback (RLHF) are crucial for aligning models with human values such as helpfulness, harmlessness, and honesty. Existing RL reward models and human alignment datasets can accelerate this process.
- Model Optimization for Inference: Strategies like distillation, quantization, and pruning help reduce the size of models, minimizing the hardware resources needed for production deployment.
- Improving Model Performance in Deployment: Techniques such as structured prompts and connecting to external data sources enhance the model's effectiveness in real-world applications.
AWS Jumpstart
Overview of Amazon SageMaker JumpStart for LLM-Powered Applications
Amazon SageMaker JumpStart is a powerful service designed to help developers quickly deploy and scale large language models (LLMs) in production environments. This service acts as a model hub and covers multiple components necessary for building end-to-end LLM-powered applications, from infrastructure to model deployment and fine-tuning.
Key Components of SageMaker JumpStart
- Model Hub:
- Foundation Models: JumpStart offers a range of foundation models, including variants of popular models like Flan-T- These models can be easily deployed and fine-tuned directly from the AWS console or SageMaker Studio.
- Integration with Hugging Face: Many of the models available through JumpStart are directly sourced from Hugging Face, facilitating seamless integration and deployment with just a few clicks.
- Infrastructure Layer:
- Compute and Storage: JumpStart provides the necessary infrastructure, including GPUs, for deploying and fine-tuning models. Users can select the instance type and size according to their requirements.
- Cost Management: It’s important to be aware that using GPUs in SageMaker is subject to on-demand pricing. AWS advises monitoring costs closely and deleting model endpoints when not in use to avoid unnecessary expenses.
- Model Deployment:
- Deployment Options: Users can deploy models to a real-time persistent endpoint by specifying key parameters like instance type and security settings. The deployment process is straightforward, allowing for quick setup.
- Security Controls: JumpStart includes options to configure security settings, ensuring that the deployed models meet specific security requirements.
- Model Fine-Tuning:
- Fine-Tuning Capabilities: JumpStart allows users to fine-tune models by providing training and validation datasets. Users can also adjust the size of the compute resources used for training through simple drop-down menus.
- Hyperparameter Tuning: The service provides easy access to tunable hyperparameters, including support for parameter-efficient fine-tuning techniques like LoRA (Low-Rank Adaptation), which can be selected directly from the interface.
- Programmatic Access:
- Notebook Generation: For users who prefer a more hands-on approach, JumpStart can automatically generate a notebook that provides all the underlying code for the deployment and fine-tuning processes. This allows developers to interact with the models programmatically and customize the implementation as needed.
Advantages of Using SageMaker JumpStart
- Rapid Deployment: JumpStart enables developers to quickly deploy LLMs in production without needing to build the infrastructure from scratch. This speeds up the time to market and allows for quick iteration and testing.
- Scalability: The service is designed to operate at scale, making it suitable for enterprises that need to manage large-scale LLM deployments.
- Ease of Use: With its user-friendly interface, pre-configured options, and integration with popular frameworks like Hugging Face, JumpStart simplifies the process of deploying, fine-tuning, and managing LLMs.
- Cost Efficiency: Although JumpStart provides robust features, it’s important to manage costs effectively by selecting appropriate compute resources and monitoring usage to prevent unnecessary expenses.