Fine-tuning with instruction
Introduction
Fine-tuning represents a significant advancement in the development of large language models (LLMs). Initially, LLMs are pretrained on vast amounts of general internet text, where they learn to predict the next word in a sequence. However, this general training doesn't make them particularly adept at following specific instructions or performing specialized tasks. Instruction fine-tuning addresses this limitation by adapting the pretrained model using a much smaller, labeled dataset tailored to specific tasks. Unlike pretraining, which relies on self-supervised learning with unstructured text, fine-tuning employs supervised learning with prompt-completion pairs. This process sharpens the model's ability to respond accurately to particular instructions, bridging the gap between broad language understanding and precise, task-specific performance, thereby making the model far more effective for specialized applications.
Instruction fine-tuning is a major breakthrough because it transforms a large language model (LLM) trained on vast amounts of general internet text, which learns to predict the next word, into a model that can follow specific instructions using a much smaller dataset. This adaptation makes the model more useful for specific tasks, bridging the gap between general language understanding and task-specific responsiveness.
Finetuning steps overview
- Define Your Task: Begin by clearly identifying the task you want the model to perform.
- Collect Relevant Data: Gather data that is directly related to the inputs and outputs of your task.
- Generate if you don't have enough data: Generate additional data or use prompt templates to create more.
- Fine-Tune a Small Model: Start by fine-tuning a smaller model, typically between 400 million to a billion parameters, to get a sense of the performance.
- Vary the Data Quantity: Experiment with different amounts of data to understand how data quantity affects model performance.
- Evaluate Model Performance: After fine-tuning, assess the model to determine what is working well and what needs improvement.
- Collect More Data Based on Evaluation: Use insights from the evaluation to gather more data and further refine the model.
- Increase Task Complexity: Once initial fine-tuning is successful, you can increase the complexity of the task.
- Scale Up the Model Size: As task complexity increases, also scale up the model size to handle the more demanding tasks effectively.
Extraction & Expansion tasks
Extraction tasks in fine-tuning primarily involve simpler, less complex activities, like reading tasks, where the model is required to understand and process input data without generating extensive outputs. These tasks typically require fewer tokens and thus can be managed effectively by smaller models. The focus here is on accurately extracting information from the input, which demands less computational power and smaller model sizes.
Expansion tasks, on the other hand, involve generating extensive outputs, such as in writing tasks like chatting, composing emails, or coding. These tasks are inherently more complex because they require the model to produce a large number of tokens, increasing the computational load. When tasks are combined, or when a model is asked to perform multiple activities simultaneously, the difficulty further escalates, necessitating the use of larger, more robust models to maintain accuracy and performance. This approach ensures the model can handle the increased complexity and deliver reliable outputs across various applications.
General Finetuning vs Instruction Finetuning
Instruction-tuning is a relatively recent development in the field of large language models (LLMs), emerging around 2021 with models like FLAN, T0, and papers on Natural Instructions. This approach focuses on training models to better follow natural language instructions, marking a shift from earlier methods that primarily involved general fine-tuning. Prior to instruction-tuning, models were often fine-tuned on specific datasets without a focus on instruction-following, which is still common today for domain-specific models like those in biomedicine or law.
Reinforcement Learning from Human Feedback (RLHF), which is even more recent, has also become important in refining models to align with human preferences. Despite these advancements, traditional fine-tuning remains relevant, especially in specialized domains where instruction-following isn't the primary concern. Distinguishing between different tuning methods—such as vanilla fine-tuning, RLHF, and instruction fine-tuning—is crucial because each can yield different performance outcomes. Categorizing models by these methods allows for more meaningful comparisons, particularly on leaderboards, where performance metrics can vary significantly depending on the tuning approach used.
- General Fine-Tuning:
- Purpose: General fine-tuning is about enhancing the model's overall knowledge, updating its data, and correcting inaccuracies.
- Knowledge Changes:
- Gain knowledge of new specific concepts: This involves updating the model with new information, allowing it to understand and generate responses about topics it previously wasn't trained on.
- Correct old incorrect information: Retraining on corrected data helps to eliminate factual errors and update the model's knowledge base.
- Instruction Fine-Tuning:
- Purpose: Instruction fine-tuning is aimed at improving the model's ability to follow specific instructions and produce more useful outputs in response to prompts.
- Behavioral Changes:
- Learning to respond more consistently: This fine-tuning trains the model to be more uniform and reliable in its responses to similar instructions.
- Learning to focus, e.g., moderation: Instruction fine-tuning can include adjusting the model to prioritize certain aspects, such as safety, moderation (which means encouraging the model to not get too off track), or ethical considerations.
- Teasing out capability, e.g., better at conversation: Fine-tuning can be used to enhance specific skills like conversation management, making the model more effective in dialogue.
Instruction Fine-Tuning
- Purpose: Instruction fine-tuning adapts a pretrained base model to follow specific instructions effectively, enhancing its utility in responding to prompts.
- Significance: It's a major breakthrough, allowing a model trained on general internet text to be refined for task-specific responses using a smaller dataset.
- Challenges: One significant issue is catastrophic forgetting, where the model forgets previously learned information during fine-tuning.
- Mitigation Techniques: Broad range instruction tuning helps prevent the model from forgetting previous knowledge by instructing it on a wide variety of tasks.
Parameter Efficient Fine-Tuning (PEFT)
- Definition: PEFT techniques optimize fine-tuning by minimizing memory and compute requirements.
- Objective: Allows tuning for specific tasks while preserving original model weights and using adaptive layers to maintain performance with a smaller memory footprint.
- 2 Popular Methods:
- Low-Rank Adaptation (LoRA): Utilizes low-rank matrices for efficient fine-tuning, achieving good performance with minimal resource use.
- Freezing Weights: Keeps original model weights unchanged and adds layers only where necessary.
- Starting with Prompting: Developers often begin with prompting, which may be sufficient for some tasks. When performance hits a ceiling, fine-tuning becomes necessary.
- Cost vs. Performance: Full fine-tuning is expensive. PEFT makes fine-tuning accessible to cost-conscious developers by reducing resource requirements.
- Model Size and Data Control: Smaller, fine-tuned models are easier to manage and deploy, especially when data control and privacy are concerns.
Instruction Fine-Tuning

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Fine-tuning exists because prompt engineering alone often can't achieve the desired performance, especially with smaller models. While prompt engineering can improve responses by providing examples (one-shot or few-shot learning), it has limitations: it doesn't always work well with smaller models and uses valuable context window space. Fine-tuning, on the other hand, adapts the model's weights using specific labeled examples, allowing the model to better understand and execute tasks without needing extensive prompt instructions. This supervised learning process leads to more accurate and efficient performance for specific applications, overcoming the inherent limitations of prompt engineering.
When you hear the term fine-tuning, most of the time you can assume that it always means instruction fine tuning.
Instruction Fine-Tuning
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
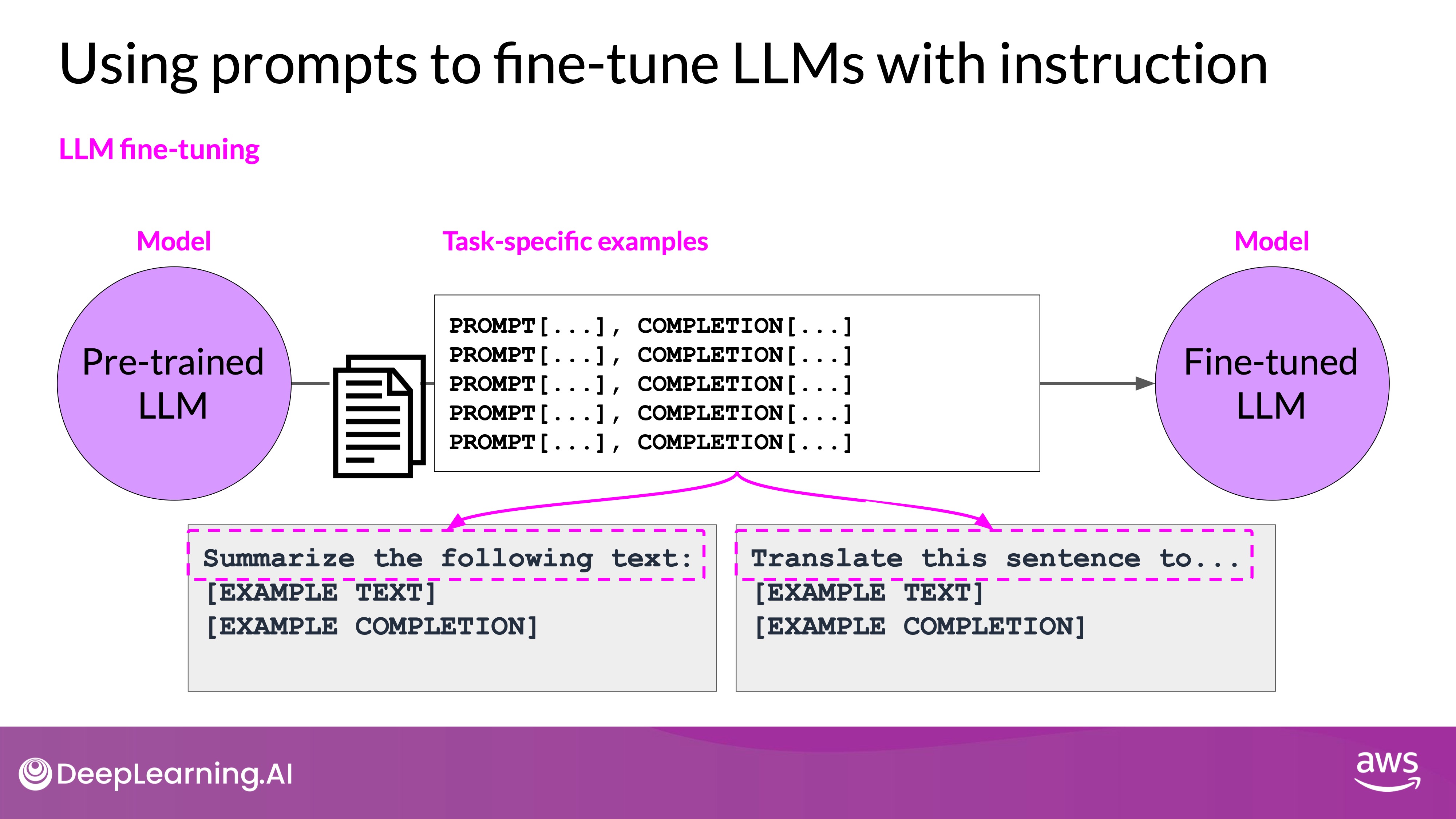
- Definition: Instruction fine-tuning uses examples that show how a model should respond to specific instructions.
- Process:
- Use labeled datasets with prompt-completion pairs.
- Examples include tasks like classification, summarization, and translation.
- The dataset includes instructions and desired completions (e.g., "classify this review" with sentiments like "positive" or "negative", summarize words or translate the words).
Instruction fine-tuning, where all of the model's weights are updated is known as full fine-tuning. The process results in a new version of the model with updated weights. This process, similar to pre-training, requires significant memory and compute resources to store and process all the gradients, optimizers, and other components being updated. Memory optimization and parallel computing strategies are essential for managing these demands.
To facilitate this, developers often use prompt template libraries, which help convert existing datasets into instruction prompt datasets. For example, templates can transform Amazon product reviews into prompts for various tasks such as classification and summarization.
Fine-Tuning Steps
- Prepare Training Data:
- Convert datasets into instruction prompts using template libraries.
 Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Divide Data: Split the dataset into training, validation, and test sets.
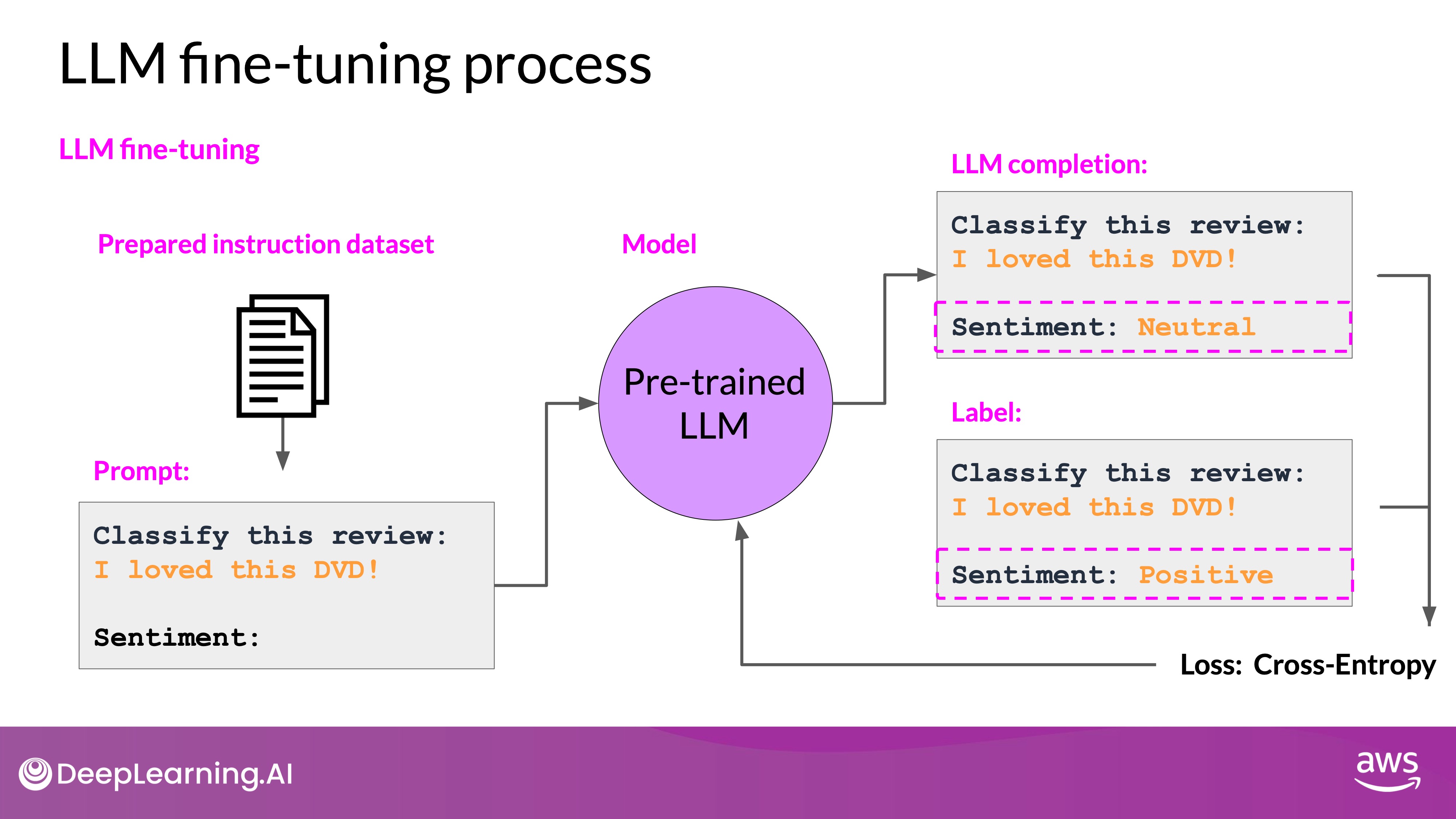
- Training Process:
- Pass prompts to the LLM and generate completions.
- Compare completions with the training labels.
- Calculate loss using the cross-entropy function to update your model weights in standard backpropagation..
- Perform this over multiple batches and epochs to improve task performance.
 Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Evaluation:
- Use the holdout validation dataset to measure validation accuracy during training.
- After fine-tuning, evaluate the model's performance using the test dataset to determine test accuracy.
- The result: The fine-tuning process results in a new version of the base model, often called an instruct model that is better at the tasks you are interested in.
Fine-tuning on a Single Task
Fine-tuning a pre-trained language model (LLM) can significantly enhance its performance on a specific task your application requires. Here’s a consolidated overview of the key points:
- Single-Task Fine-Tuning: This process involves adapting a pre-trained LLM to improve its performance on one particular task, such as summarization or sentiment analysis, using a dataset specific to that task.
- Data Efficiency: Surprisingly, fine-tuning on a single task often requires only 500-1,000 examples to achieve good results, compared to the billions of texts seen during the model’s pre-training phase.
- Catastrophic Forgetting [Important!]:
- A potential downside to single-task fine-tuning is catastrophic forgetting. This occurs because the fine-tuning process alters the original model’s weights, enhancing the specific task performance but possibly degrading performance on other tasks.
- Examples of Catastrophic Forgetting: A model fine-tuned for sentiment analysis might lose its ability to perform named entity recognition correctly. For instance, it may no longer identify "Charlie" as a cat's name in a sentence.
- Assessing Impact: Determine if catastrophic forgetting affects your use case. If the model's sole focus is the fine-tuned task, it may not be problematic. However, if multitask capability is required, further steps are necessary.
- How to solve Catastrophic Forgetting?: If you do want or need the model to maintain its multitask generalized capabilities, you can perform..
- Multitask Fine-Tuning: To retain the model's generalized multitask capabilities, fine-tune it on multiple tasks simultaneously. This requires more data and computational resources, typically 50-100,000 examples across various tasks.
- Parameter Efficient Fine-Tuning (PEFT): PEFT techniques maintain the original LLM weights while training only a small number of task-specific adapter layers and parameters. This approach is more robust against catastrophic forgetting and is a vibrant research area. PEFT will be covered in more detail later in the course.
Multi-task Instruction Fine-tuning
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
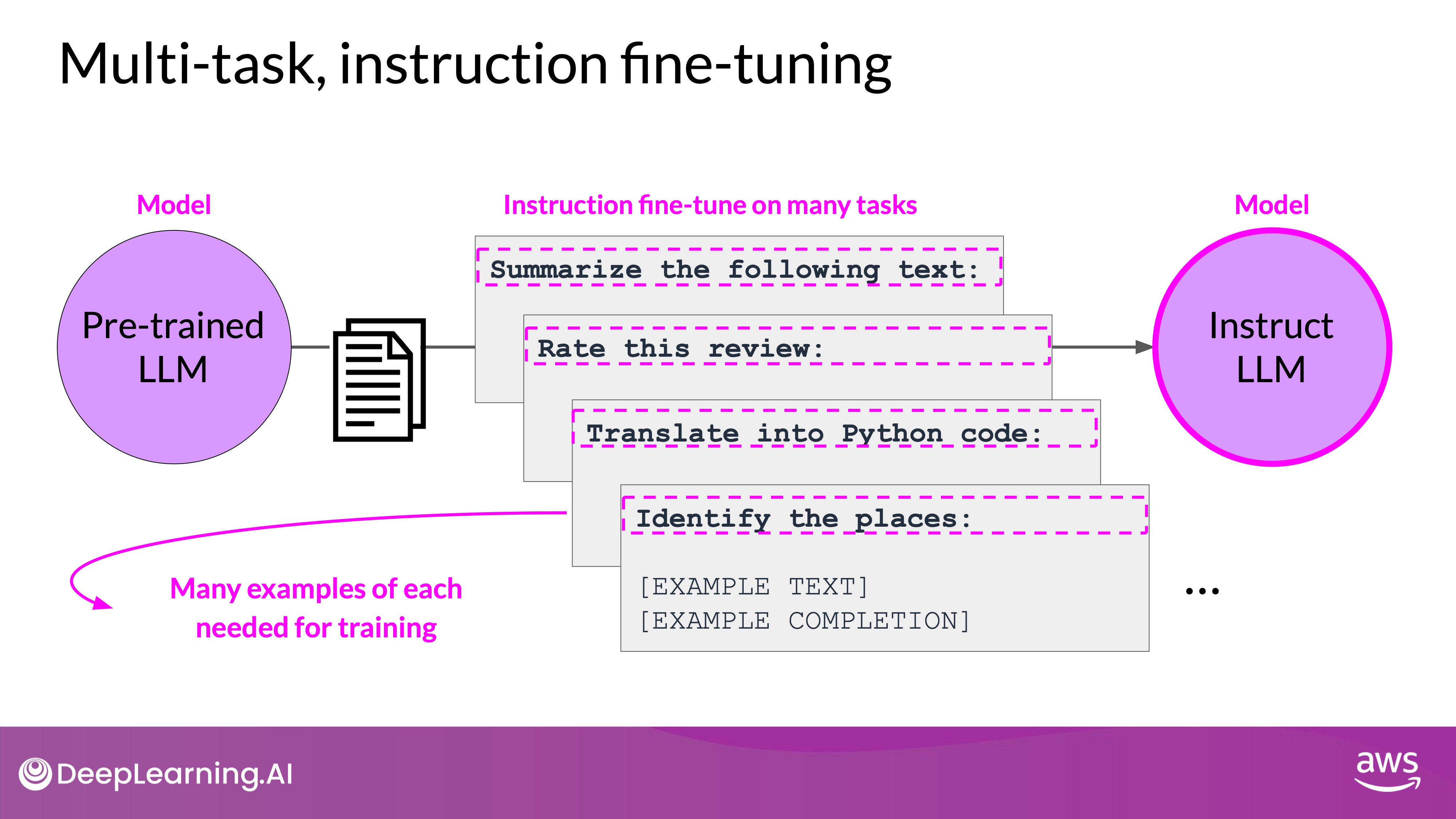
Multitask fine-tuning extends the concept of single task fine-tuning by using a training dataset that includes example inputs and outputs for multiple tasks. This approach trains the model on a diverse dataset that instructs it to perform a variety of tasks, such as summarization, review rating, code translation, and entity recognition. This comprehensive training helps the model improve its performance across all tasks simultaneously, mitigating the issue of catastrophic forgetting.
During training, losses are calculated and used to update the model's weights over many epochs, resulting in an instruction-tuned model proficient in multiple tasks. Despite its advantages, multitask fine-tuning requires a substantial amount of data, often between 50,000 and 100,000 examples. However, the effort to gather this data is justified by the resulting models' enhanced capabilities, making them suitable for situations requiring robust performance across various tasks.
FLAN (multitask instruction fine-tuning LLM)
One notable family of models trained using multitask instruction fine-tuning is the FLAN (Fine-Tuned Language Net) family. FLAN fine-tuning represents the final step in the training process, metaphorically referred to as the "dessert" following the "main course" of pre-training. FLAN models, such as FLAN-T5 and FLAN-PALM, are fine-tuned versions of foundational models like T5 and PALM.
- FLAN-T5: A general-purpose instruct model fine-tuned on 473 datasets across 146 task categories. These datasets are sourced from various models and research papers.
- SAMSum Dataset (Hugging Face - Samsung/samsum): It's part of the Muffin collection of tasks and datasets. It's used for summarization tasks within FLAN-T5, this dataset includes 16,000 messenger-like conversations with summaries crafted by linguists to generate high-quality training data for language models.
- Here is a prompt template designed to work with this SAMSum dialogue summary dataset. The template is actually comprised of several different instructions that all basically ask the model to do this same thing. Summarize a dialogue.
 Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Scaling instruct models
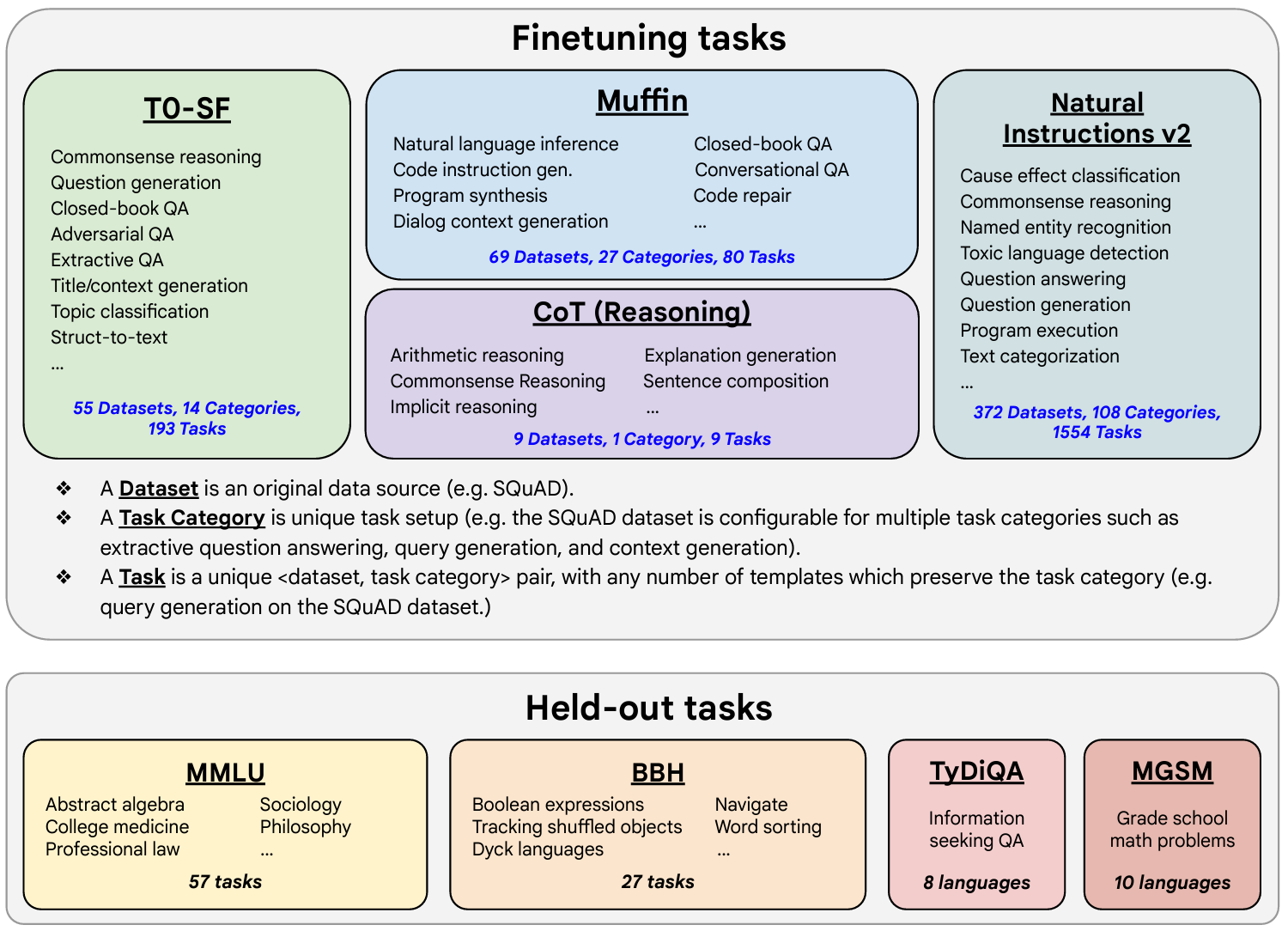
Here is the image that illustrates the fine-tuning tasks and datasets employed in training FLAN. The task selection expands on previous works by incorporating dialogue and program synthesis tasks from Muffin and integrating them with new Chain of Thought Reasoning tasks. It also includes subsets of other task collections, such as T0 and Natural Instructions v2. Some tasks were held-out during training, and they were later used to evaluate the model's performance on unseen tasks.
Source: arxiv: Scaling Instruction-Finetuned Language Models
- T0-SF: T0-SF (T0 Supervised Fine-tuning) involves fine-tuning a pretrained language model on multiple supervised datasets to enhance task-specific performance through explicit training examples.
- Muffin: Muffin is a collection of diverse tasks and datasets used in the FLAN fine-tuning process to ensure the model's versatility and generalization across different instructions.
- Cot: Cot (Chain of Thought) involves using intermediate reasoning steps to help the model break down complex tasks into simpler sub-tasks, improving performance on tasks requiring multi-step reasoning.
- Natural Instructions: Natural Instructions consist of human-written task descriptions and examples designed to guide the model in understanding and performing a wide variety of tasks accurately.
Fine-tuning with Custom Data
While FLAN-T5 performs well across many tasks, specific use cases may require additional fine-tuning with domain-specific datasets. For instance, a data scientist developing an app for summarizing customer service chats can further fine-tune FLAN-T5 using the DialogSum dataset, which contains over 13,000 support chat dialogues and summaries. This additional fine-tuning helps the model better handle customer service conversations, improving its ability to produce accurate and relevant summaries.
DialogSum Dataset provides dialogues typical of customer support interactions, enabling the model to learn the specifics of such conversations. Fine-tuning with this data can significantly enhance the model's performance, making it more aligned with the desired application.
- Fine-tuning on custom data, such as a company's internal support chat conversations, allows the model to learn the nuances of how the company prefers to summarize dialogues, benefiting customer service teams. Evaluating the quality of the model's completions is crucial, and various metrics and benchmarks can be used to assess performance improvements post-fine-tuning.
- Although FLAN-T5 is a capable model, it can still benefit from additional fine-tuning on specific tasks.
Model Evaluation in Large Language Models
Evaluating the performance of large language models involves using various metrics to formalize improvements and compare models. Unlike traditional machine learning models, where accuracy on deterministic outputs is straightforward (Formula: ), evaluating language models requires more nuanced approaches due to their non-deterministic and language-based outputs.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Metrics A: ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Primarily used to assess the quality of automatically generated summaries by comparing them to human-generated references. ROUGE metrics include:
- Fixed number of words:
- ROUGE-1: Measures unigram (single word) overlap.
- ROUGE-2: Measures bigram (two-word) overlap.
 Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- ROUGE-L: Considers the longest common subsequence to account for word order.
 Source:
Source: For example, comparing "It is cold outside" and "It is very cold outside," ROUGE-1 might show perfect recall but requires bigrams or longer sequences to reflect word order and context.
As with all of the rouge scores, you need to take the values in context. You can only use the scores to compare the capabilities of models if the scores were determined for the same task. For example, summarization. Rouge scores for different tasks are not comparable to one another.
A particular problem with simple rouge scores is that it's possible for a bad completion to result in a good score. Take a look a below example.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
However, you'll still be challenged if their generated words are all present, but just in a different order. For example, with this generated sentence, outside cold it is. This sentence was called perfectly even on the modified precision with the clipping function as all of the words and the generated output are present in the reference. Whilst using a different rouge score can help experimenting with a n-gram size that will calculate the most useful score will be dependent on the sentence, the sentence size, and your use case.
Whilst using a different rouge score can help experimenting with a n-gram size that will calculate the most useful score will be dependent on the sentence, the sentence size, and your use case.
Metrics B: BLEU
BLEU (Bilingual Evaluation Understudy)
Used to evaluate machine-translated text quality by comparing the n-grams in the machine translation to those in the human reference translation. BLEU scores range from 0 to 1, with higher scores indicating closer matches to the reference translation.
For instance, comparing "I am very happy to say that I am drinking a warm cup of tea" to "I am very happy that I am drinking a cup of tea," BLEU calculates an average precision across varbleuious n-gram sizes. As we get closer and closer to the original sentence, we get a score that is closer and closer to one.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Use Benchmarks along with ROUGE and BLEU
Both metrics, while simple and low-cost to calculate, have limitations. They can misinterpret meaning if word order or context is not properly accounted for. You can use them for simple reference as you iterate over your models, but you shouldn't use them alone to report the final evaluation of a large language model. Use rouge for diagnostic evaluation of summarization tasks and BLEU for translation tasks.
For comprehensive model evaluation, it is essential to use established benchmarks in addition to ROUGE and BLEU. These benchmarks provide a broader assessment of a model's performance across various tasks and scenarios, ensuring a more accurate evaluation.
Error Analysis in LLMs
Error analysis in machine learning typically requires training the model first. However, in the context of fine-tuning LLMs, you can perform error analysis even before fine-tuning because you have a pre-trained base model. This early analysis helps in understanding the model's initial performance, allowing for targeted improvements during fine-tuning.
Before fine-tuning, analyzing the base model helps you identify its strengths and weaknesses. This analysis allows you to determine what types of data will most effectively enhance the model's performance during fine-tuning. It serves as a diagnostic tool to optimize the dataset for better results. Below are the common error categories in LLMs
- Misspellings: A straightforward category of errors involves misspellings in the dataset. Correcting these errors is crucial for improving the accuracy of the model's output. For example, in a dataset, correcting a typo like "liver" instead of "lover" ensures the model learns the correct context and meaning.
- Length and Verbosity:
- Verbosity Issues: LLMs, including generative models like ChatGPT, are often overly verbose. This verbosity can dilute the quality of responses. One approach is to refine the dataset to encourage more succinct answers, leading to more direct and concise outputs.
- Training Adjustments: During training, adjustments like those made in the training notebook can help reduce verbosity and repetitiveness, contributing to clearer, more focused responses.
| Common Error Category | Example with Problem | Example Fixed |
|---|---|---|
| Misspellings | "Go get your liver checked" (intended to be "lover") | "Go get your lover checked" |
| Length and Verbosity | "The model was trained using a very large dataset that contained a lot of different examples and variations, which made it perform quite well in a variety of tasks, and it also helped in generalizing better to unseen data, though sometimes it could still be verbose and repetitive in its answers." | "The model was trained on a large dataset, improving performance and generalization, but it can still be verbose." |
| Repetitiveness | "The cat is on the mat. The cat is on the mat. The cat is on the mat." | "The cat is on the mat." |
Repetitiveness is a common issue in outputs generated by large language models (LLMs). This can be effectively mitigated through the use of stop tokens and carefully designed prompt templates, which guide the model towards producing more varied and less repetitive responses. Additionally, ensuring that your dataset includes a diverse range of examples with minimal repetition is another crucial strategy. This diversity helps the model learn to generate more varied and engaging content, reducing the likelihood of repetitive outputs and enhancing the overall quality of the generated text.
Benchmarks
Evaluating large language models (LLMs) requires comprehensive benchmarks that go beyond simple metrics like ROUGE and BLEU in order to measure and compare LLMs more holistically. These benchmarks use pre-existing datasets to measure and compare the holistic capabilities of LLMs, focusing on specific skills and potential risks.
Using the right evaluation dataset is crucial for accurately assessing an LLM's performance. It's best to use data the model hasn't seen before during training to avoid biased results. Benchmarks help isolate specific skills like reasoning and common sense knowledge and address potential risks like disinformation or copyright infringement.
Key Benchmarks
- GLUE (General Language Understanding Evaluation): Introduced in 2018, GLUE includes a collection of natural language tasks such as sentiment analysis and question answering, encouraging models to generalize across multiple tasks.
- SuperGLUE: Launched in 2019 as a successor to GLUE, SuperGLUE features more challenging tasks, including multi-sentence reasoning and reading comprehension. Both GLUE and SuperGLUE have leaderboards to compare model performances.
As models get larger, their performance against benchmarks such as SuperGLUE start to match human ability on specific tasks. That's to say that models are able to perform as well as humans on the benchmarks tests, but subjectively we can see that they're not performing at human level at tasks in general. There is essentially an arms race between the emergent properties of LLMs, and the benchmarks that aim to measure them.
- MMLU (Massive Multitask Language Understanding): Designed for modern LLMs, MMLU tests extensive world knowledge and problem-solving abilities across subjects like elementary mathematics, US history, computer science, and law. In other words, tasks that extend way beyond basic language understanding.
- BIG-bench: Consisting of 204 tasks across diverse fields such as linguistics, childhood development, math, common sense reasoning, and software development. BIG-bench is available in different sizes to manage inference costs.
- ARC: The AI2 Reasoning Challenge is designed to test a model's ability to answer grade-school science questions that require reasoning beyond simple factual recall. It assesses the model's understanding of scientific concepts, deductive reasoning, and its ability to apply knowledge in novel contexts.
- HellaSwag: This benchmark tests a model's commonsense reasoning by challenging it to predict the most plausible continuation of a given scenario. The task requires the model to understand context, sequence of events, and the subtleties of human behavior and interactions.
- HELM (Holistic Evaluation of Language Models): HELM aims to improve model transparency and guidance for specific tasks. It uses a multi-metric approach, assessing seven metrics across 16 core scenarios, including fairness, bias, and toxicity, which are becoming increasingly important to assess as LLMs become more capable of human-like language generation, and in turn of exhibiting potentially harmful behavior.
 Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Using Benchmarks
Benchmarks like GLUE, SuperGLUE, MMLU, BIG-bench, and HELM provide valuable insights into LLM capabilities. They help track progress, compare models, and ensure a model's performance aligns with the desired application, considering various factors beyond basic accuracy.
For comprehensive evaluations, it's essential to refer to the results pages of these benchmarks, which offer detailed comparisons and metrics relevant to specific projects.
While ARC and similar benchmarks are commonly used to rank models, it's important to recognize that they may not correlate with real-world use cases. The performance of a model on these benchmarks doesn't necessarily reflect how well it will perform on tasks that are specific to your needs or business objectives.
Importance of Use Case Alignment: Fine-tuning models allows them to be tailored to a wide variety of tasks, each requiring different evaluation metrics. Therefore, it's essential to focus on the evaluation metrics that are relevant to your specific use case rather than getting too caught up in benchmark rankings, which might not align with your goals.