Transformer, Prompt engineering, Config
Pre-training in the context of Large Language Models (LLMs) is essentially the same fundamental action as training in the broader AI field. Both involve updating model weights based on a dataset to minimize some loss function, but the terminology emphasizes different aspects of the process. In LLMs, "pre-training" is emphasized to distinguish this foundational training phase from "fine-tuning," which adapts the pre-trained model to specific tasks.
- Course overview:
- Use Cases for LLMs: Common applications include essay writing, dialogue summarization, and translation.
- Transformer Architecture: Understanding the architecture and inference parameters to influence model output.
- Generative AI Project Lifecycle: A structured approach to planning and developing generative AI applications.
- Pre-training and Computational Challenges: The significance of pre-training on vast text data, memory limitations, and the use of quantization.
- Scaling Laws: The role of scaling laws in designing compute-optimal models and balancing model parameters, dataset size, and compute budget.
- Week 1: Transformer Architecture and Model Training
- Understanding the transformer architecture behind large language models (LLMs).
- Learning about the training process of these models.
- Exploring the compute resources necessary for developing LLMs.
- Introduction to in-context learning.
- Guidance on prompt engineering for better inference output.
- Tuning important generation parameters for refining model outputs.
- Week 2: Adapting Pre-trained Models
- Adapting pre-trained models for specific tasks and datasets.
- Instruction fine-tuning process.
- Week 3: Aligning Model Outputs with Human Values
- Aligning LLM outputs with human values to enhance helpfulness and reduce harm/toxicity.
- Each week includes hands-on labs in an AWS environment, providing practical experience with large models.
- Hands-on Labs Overview
- Lab 1
- Construct and compare different prompts and inputs for dialogue summarization.
- Explore inference parameters and sampling strategies to improve generative model responses.
- Lab 2:
- Fine-tune an existing LLM from Hugging Face.
- Experiment with full fine-tuning and parameter-efficient fine-tuning (PEFT).
- Lab 3:
- Work with reinforcement learning from human feedback (RLHF).
- Build a reward model classifier to label model responses as toxic or non-toxic.
- Lab 1
Overview
Inference in the context of Large Language Models (LLMs) refers to the process of using a pre-trained and possibly fine-tuned model to generate predictions or responses based on new input data. During inference, the model applies the knowledge it acquired during training to produce outputs for given prompts. Unlike training, inference does not involve updating the model's weights; it solely focuses on utilizing the existing trained parameters to interpret and respond to inputs. This process can include tasks such as text generation, translation, summarization, or answering questions based on the prompt provided.
Large language models (LLMs) with more parameters are better suited to handle a wide variety of tasks and can provide accurate completions through zero-shot inference due to their increased representational power and better generalization capabilities. These models can capture and learn complex patterns and relationships within vast and diverse datasets, allowing them to understand and generate text across different domains effectively. Their ability to represent rich and diverse features of language enables them to perform tasks they weren't explicitly trained for, showcasing emergent properties such as zero-shot learning.
However, when it comes to specific areas, smaller LLMs with fewer parameters can sometimes outperform larger models because they can be fine-tuned to overfit particular tasks, making them highly specialized and efficient for those tasks. Smaller models focus on a narrower set of features and patterns relevant to a specific task, resulting in better performance within that area. Additionally, smaller models require less computational power and memory, leading to faster training and inference times, making them more practical and resource-efficient for specialized applications. Thus, while larger models excel in generalization and versatility, smaller models can offer superior performance in specialized tasks due to their focused training and resource efficiency.
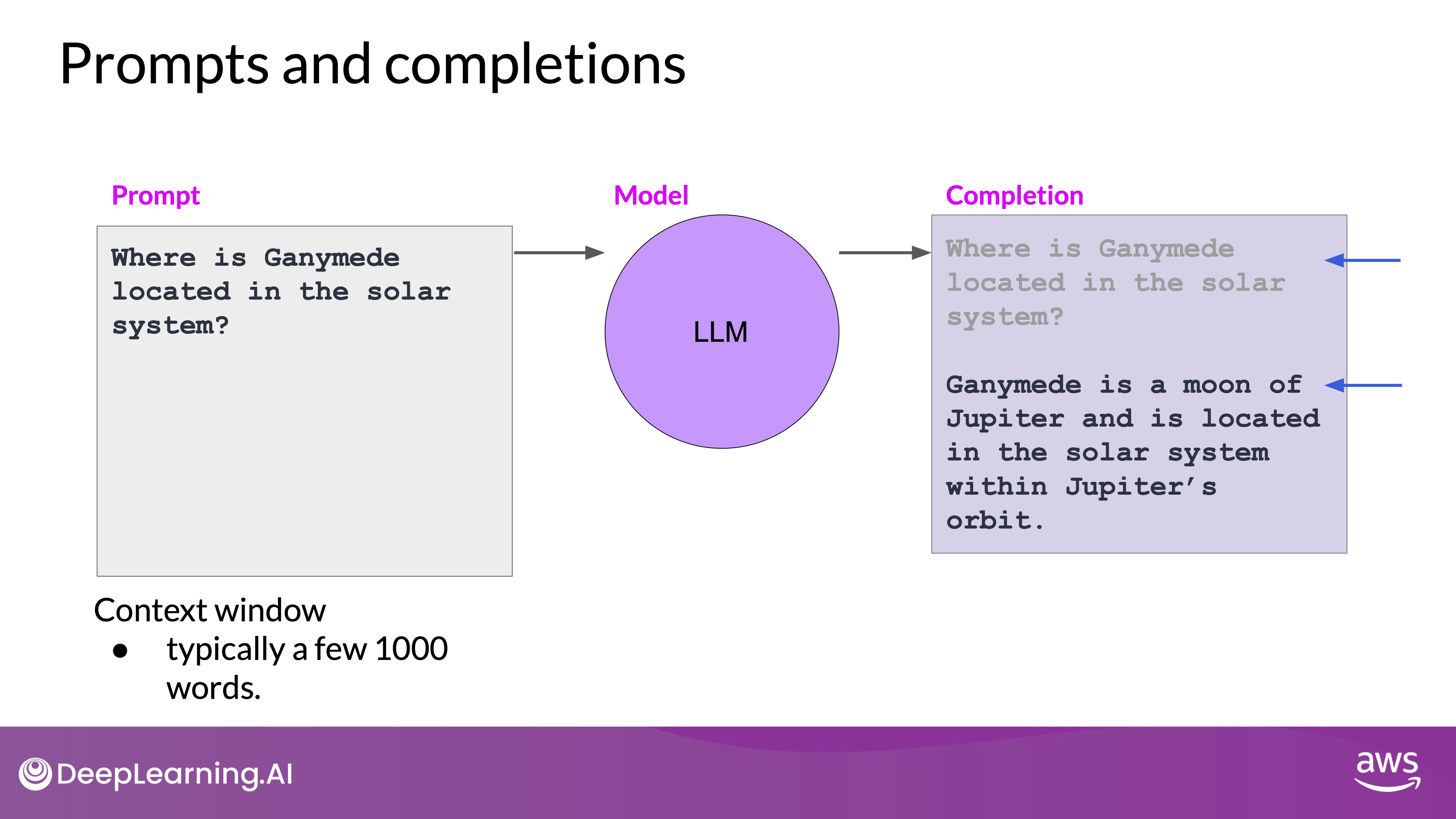
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Key Terminology:
- Interaction with LLMs is through natural language or human-written instructions, known as prompts.
- The prompt is processed by the model to predict and generate text (inference).
- The output generated by the model is called a completion.
- Context Window: The amount of text/memory available for the prompt.
Practical Applications
- Use Cases and Applications:
- Adapting models for specific tasks through fine-tuning.
- Deploying LLMs in applications to solve business and social tasks.
- Interaction Paradigms:
- Different from traditional machine learning and programming, LLMs use natural language instructions.
- Context window: The memory space available for the prompt, typically large enough for a few thousand words, varies by model.
Use cases
Large Language Models (LLMs) and generative AI are often associated with chat-based applications, like chatbots, due to their high visibility and widespread attention. However, the fundamental concept of next-word prediction extends far beyond simple chat tasks, enabling a wide array of applications within text generation and beyond.
- Text Generation Tasks:
- Essay Writing:
- Description: Given a prompt, an LLM can generate an entire essay. This involves understanding the context, generating coherent and relevant content, and structuring the text appropriately.
- Example: "Write an essay on the impact of climate change on polar bears."
- Summarization:
- Description: LLMs can summarize long pieces of text, such as dialogues, articles, or reports, by extracting key points and condensing the information into a shorter form.
- Example: Summarizing a meeting transcript to highlight main decisions and action items.
- Essay Writing:
- Translation Tasks:
- Natural Language Translation:
- Description: Translating text between different human languages, such as English to Spanish or French to German.
- Example: Translating an English news article into French.
- Code Generation:
- Description: Translating natural language instructions into programming code. LLMs can generate code snippets in various programming languages based on descriptive prompts.
- Example: "Write a Python function to calculate the mean of each column in a DataFrame."
- Natural Language Translation:
- Information Retrieval and Classification:
- Named Entity Recognition (NER):
- Description: Identifying and classifying entities such as names of people, places, and organizations within a text.
- Example: Extracting all names and locations from a news article.
- Question Answering:
- Description: Responding to questions posed in natural language by extracting relevant information from a given text or dataset.
- Example: Answering questions about a specific event described in a text passage.
- Named Entity Recognition (NER):
- Advanced Application(External Data Source Integration):
- Description: Augmenting LLMs by connecting them to external databases or APIs, allowing them to fetch real-time data or perform actions based on up-to-date information.
- Example: Using an LLM to fetch weather data from an external API and provide a weather forecast.
History
For more details, check History of LLM
Before the advent of transformers, generative algorithms relied on Recurrent Neural Networks (RNNs), which were constrained by their computational and memory demands. RNNs struggled with long-term dependencies, making them inadequate for understanding complex language structures. Despite scaling, RNNs often failed at tasks like next-word prediction due to their limited ability to retain contextual information over long sequences. The breakthrough came in 2017 with the transformer architecture, introduced by the paper "Attention is All You Need." Transformers efficiently handle larger datasets and parallel processing, focusing on the contextual meaning of words, revolutionizing generative AI capabilities.
Transformer
Building large language models using the transformer architecture dramatically improved the performance of natural language tasks over the earlier generation of RNNs, leading to an explosion in regenerative capability.
Key Attributes of Transformer Architecture
- Self-Attention Mechanism: Transformers excel by learning the relevance and context of every word in a sentence relative to every other word. This mechanism, known as self-attention, allows the model to apply attention weights, thus understanding complex relationships and dependencies within the text.
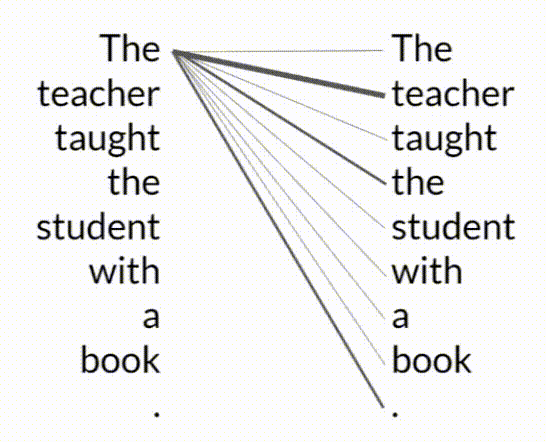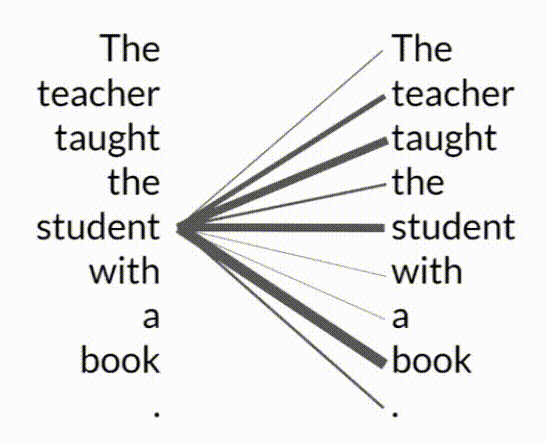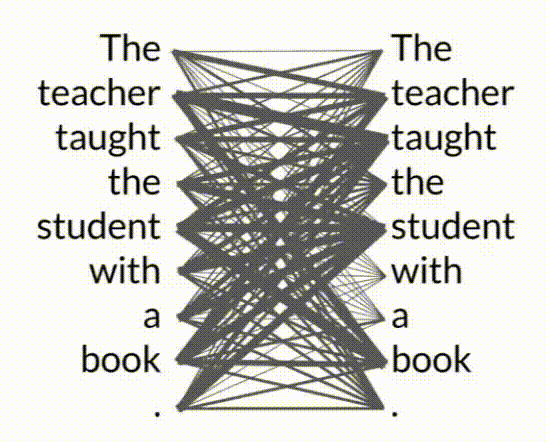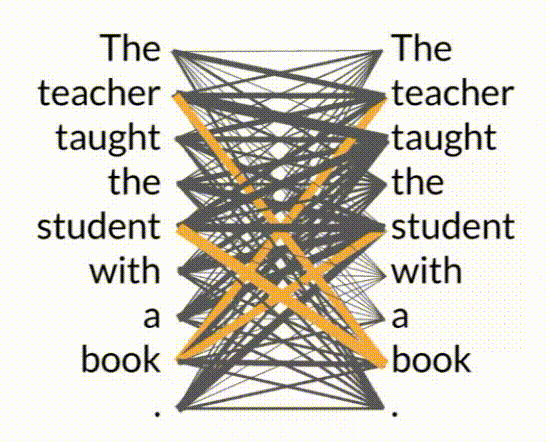
- Attention Map:
- An attention map visualizes the attention weights between each word and all other words in a sentence, illustrating how the model prioritizes different parts of the input.
- The word book is strongly connected with or paying attention to the word teacher and the word student. This is called self-attention and the ability to learn a tension in this way across the whole input significantly approves the model's ability to encode language.
Embedding layer
Source: Attention is all you need
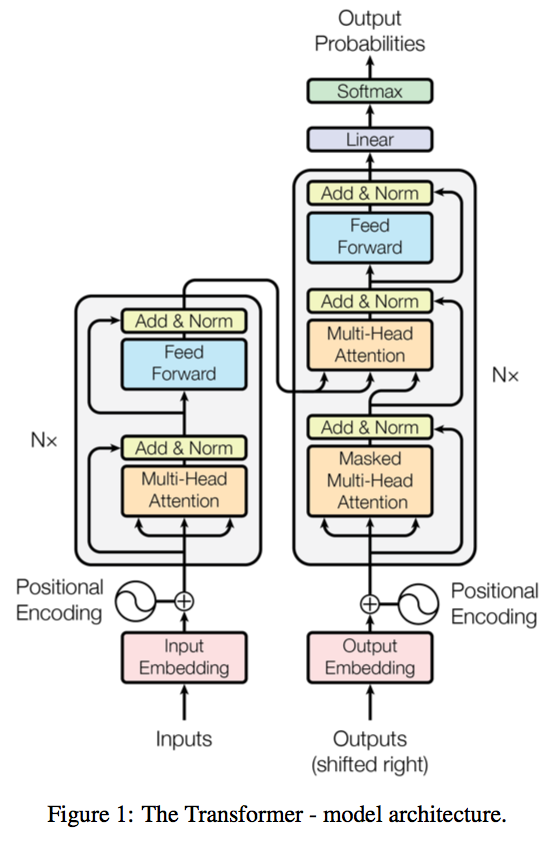
- Encoder and Decoder: The transformer model is divided into two main components: the encoder and the decoder. Both parts share similar functionalities but serve different roles in processing and generating text.
- Tokenization:
-
Before processing text, it is tokenized into numbers, with each number representing a position in a predefined dictionary. This step is crucial for converting words into a format the model can understand.
-
You can choose from multiple tokenization methods. For example, token IDs matching two complete words, or using token IDs to represent parts of words.
-
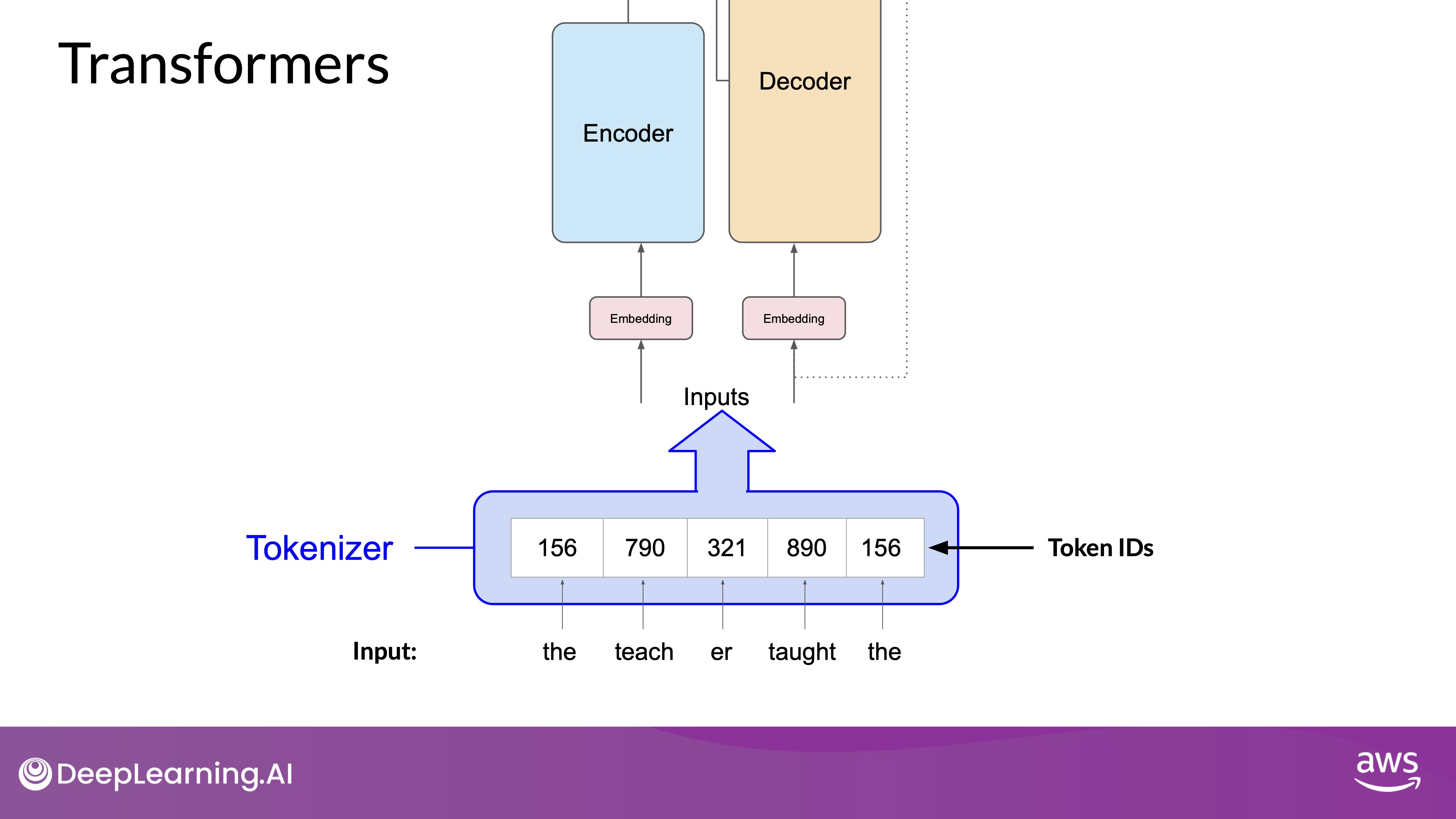
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
-
- Embedding Layer:
-
This layer is a trainable vector embedding space. Tokens are transformed into vectors in a high-dimensional space, where each vector encodes the meaning and context of the corresponding token. These embeddings enable the model to mathematically interpret language.
-
Embedding vector spaces have been used in natural language processing for some time, previous generation language algorithms like Word2vec use this concept.
-
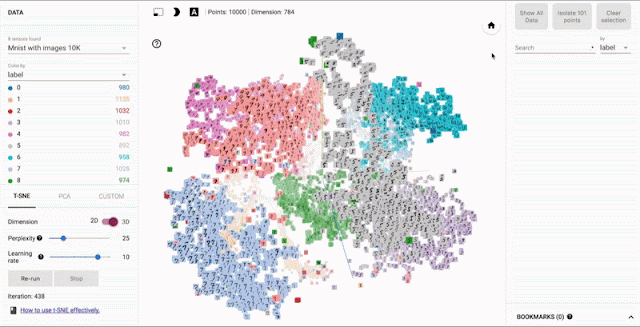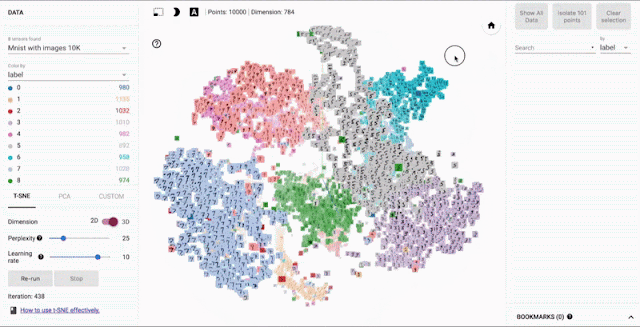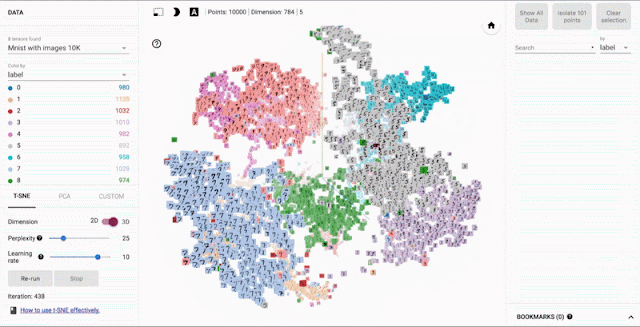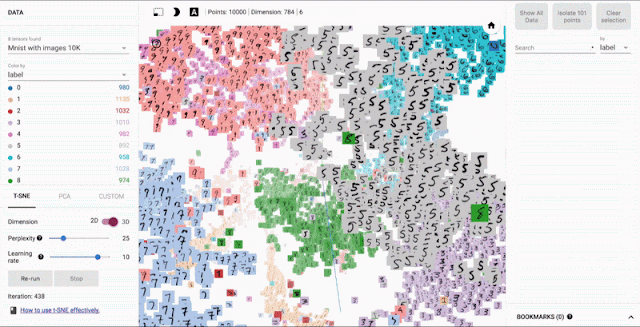
Source: Google - Open sourcing the Embedding Projector: a tool for visualizing high dimensional data
-
- Positional Encoding:
-
Positional encodings are added to the input tokens to preserve the order of words in a sentence, which is essential since transformers process tokens in parallel and not sequentially.
-
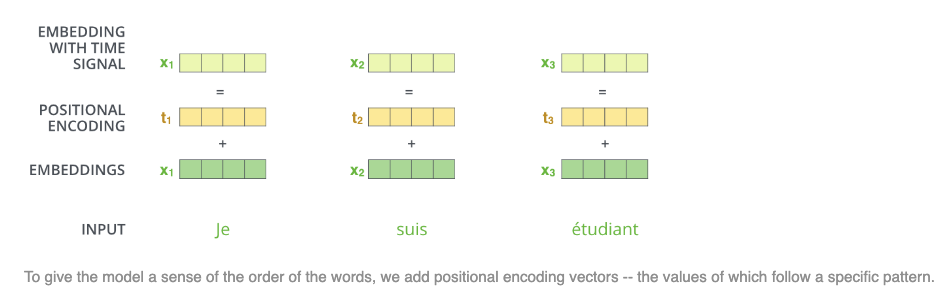
-
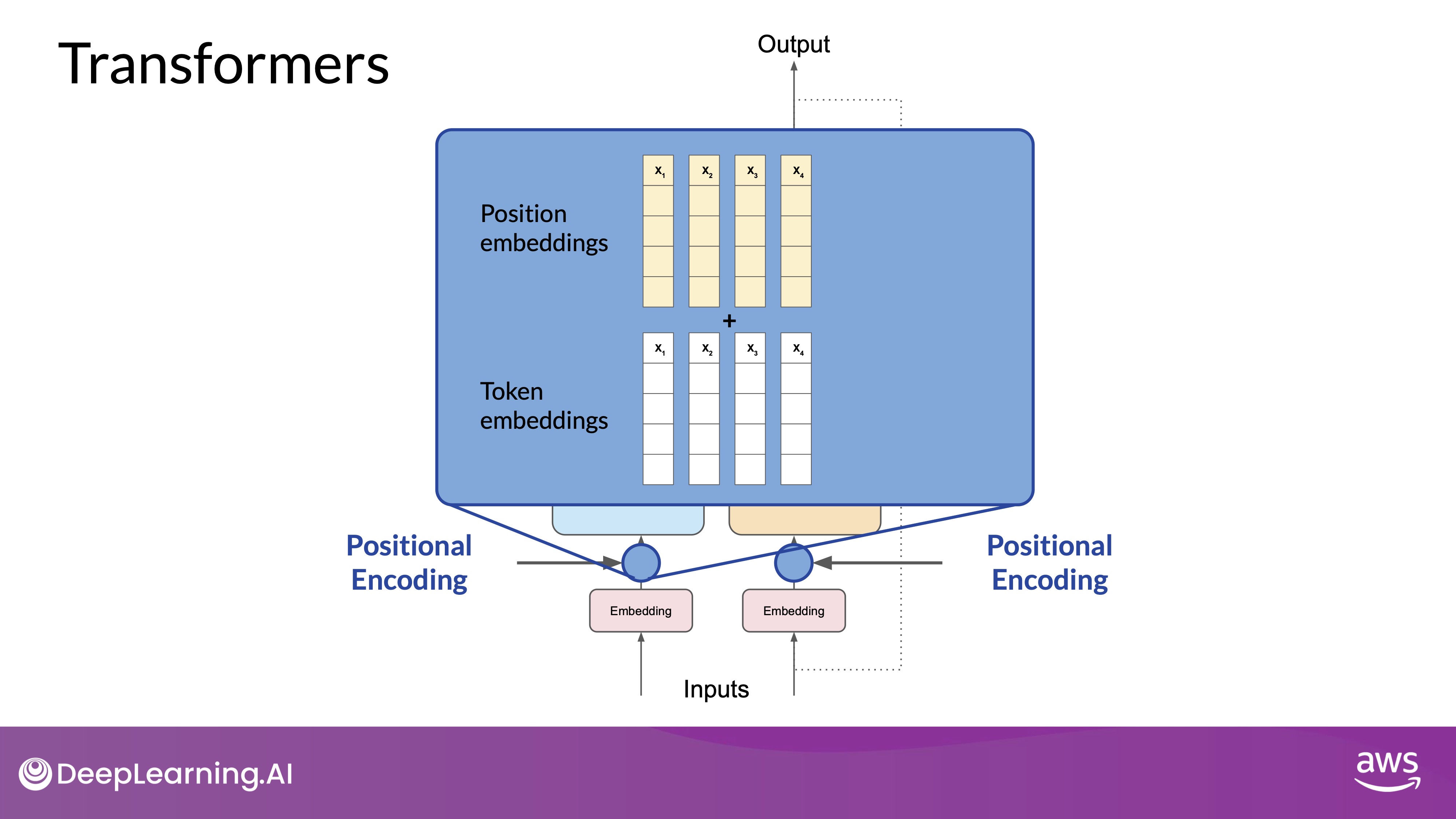
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
-
Encode and Decode layers
- Multi-Headed Self-Attention Layer:
- The self-attention layer evaluates the relationships between tokens, allowing the model to focus on different parts of the input sequence and understand contextual dependencies.
- Multiple self-attention heads are used in parallel, with each head learning different aspects of the language independently. This enables the model to capture diverse linguistic features simultaneously. The number of attention heads included in the attention layer varies from model to model, but numbers in the range of 12-100 are common.
- The intuition here is that each self-attention head will learn a different aspect of language. For example, one head may see the relationship between the people entities in our sentence. Whilst another head may focus on the activity of the sentence. Whilst yet another head may focus on some other properties such as if the words rhyme.
- Feed-Forward Network: After applying attention weights, the data is passed through a feed-forward neural network. This network outputs a vector of logits, which represent the probability scores for each token in the dictionary.
- Softmax Layer:
- The vector of logits are normalized using a softmax function, producing a probability distribution over all possible tokens. The token with the highest probability is selected as the most likely prediction.
- This output includes a probability for every single word in the vocabulary, so there's likely to be thousands of scores here. One single token will have a score higher than the rest. This is the most likely predicted token.
- Attention weights are learned during the training phase and are crucial for the model's ability to understand and generate coherent text.
- Tokenization must remain consistent during both training and text generation to ensure the model's effectiveness.
- The model outputs a probability score for each token, and various methods can be applied to select the final token, influencing the generated text's diversity and coherence.
Generating Text with Transformers
In this example, you'll look at a translation task or a sequence-to-sequence task, which incidentally was the original objective of the transformer architecture designers. We'll translate the French phrase to English using a transformer model.
End-to-End Prediction Process
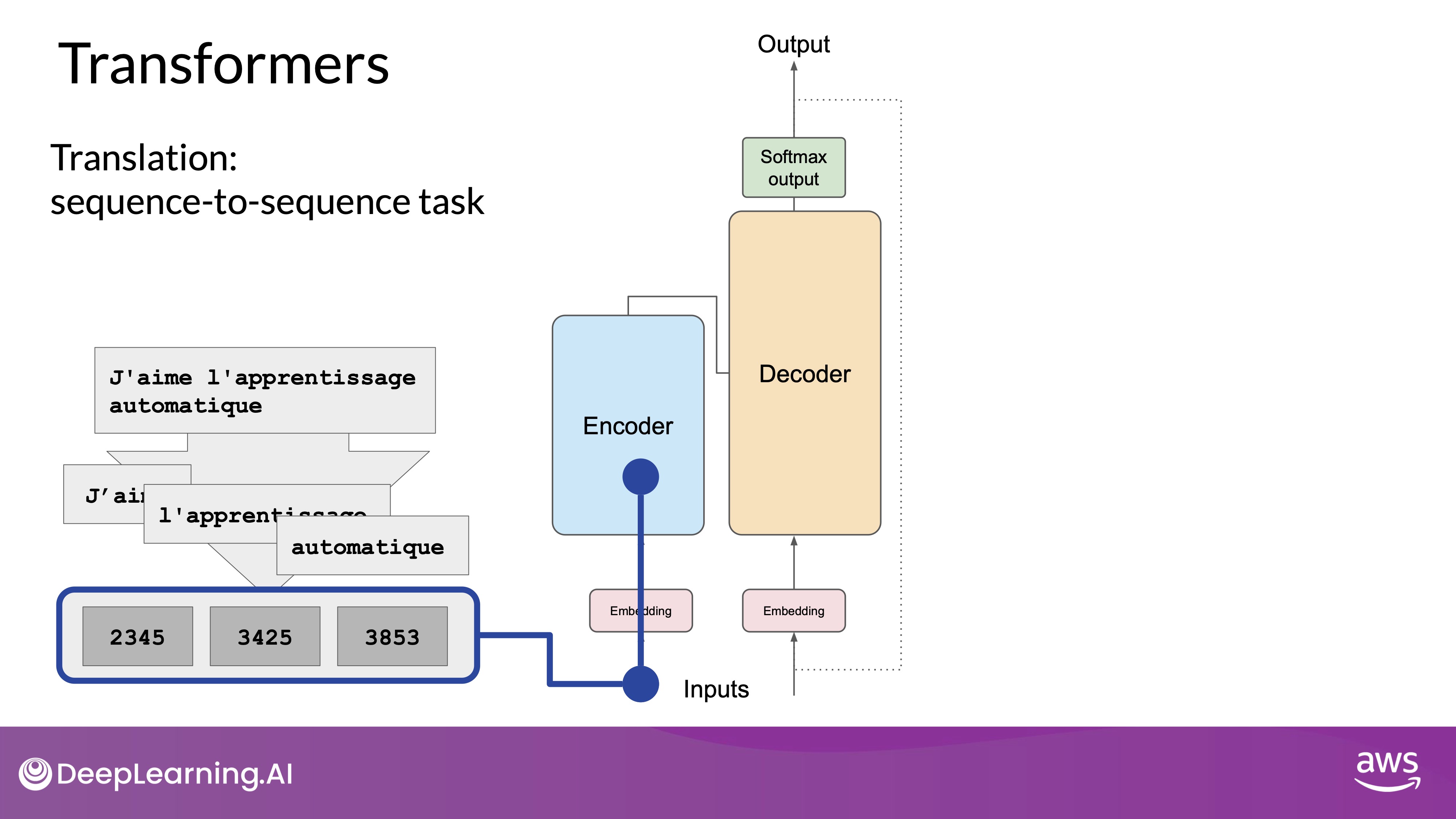
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Tokenization:
- The input words are tokenized using the same tokenizer used during training.
- These tokens are input into the encoder side of the network.
- Encoder Process:
- Tokens pass through the embedding layer.
- They are fed into multi-headed attention layers.
- Outputs from the attention layers go through a feed-forward network.
- The encoder outputs a deep representation of the input sequence's structure and meaning.
At this point, the data that leaves the encoder is a deep representation of the structure and meaning of the input sequence. This representation is inserted into the middle of the decoder to influence the decoder's self-attention mechanisms.
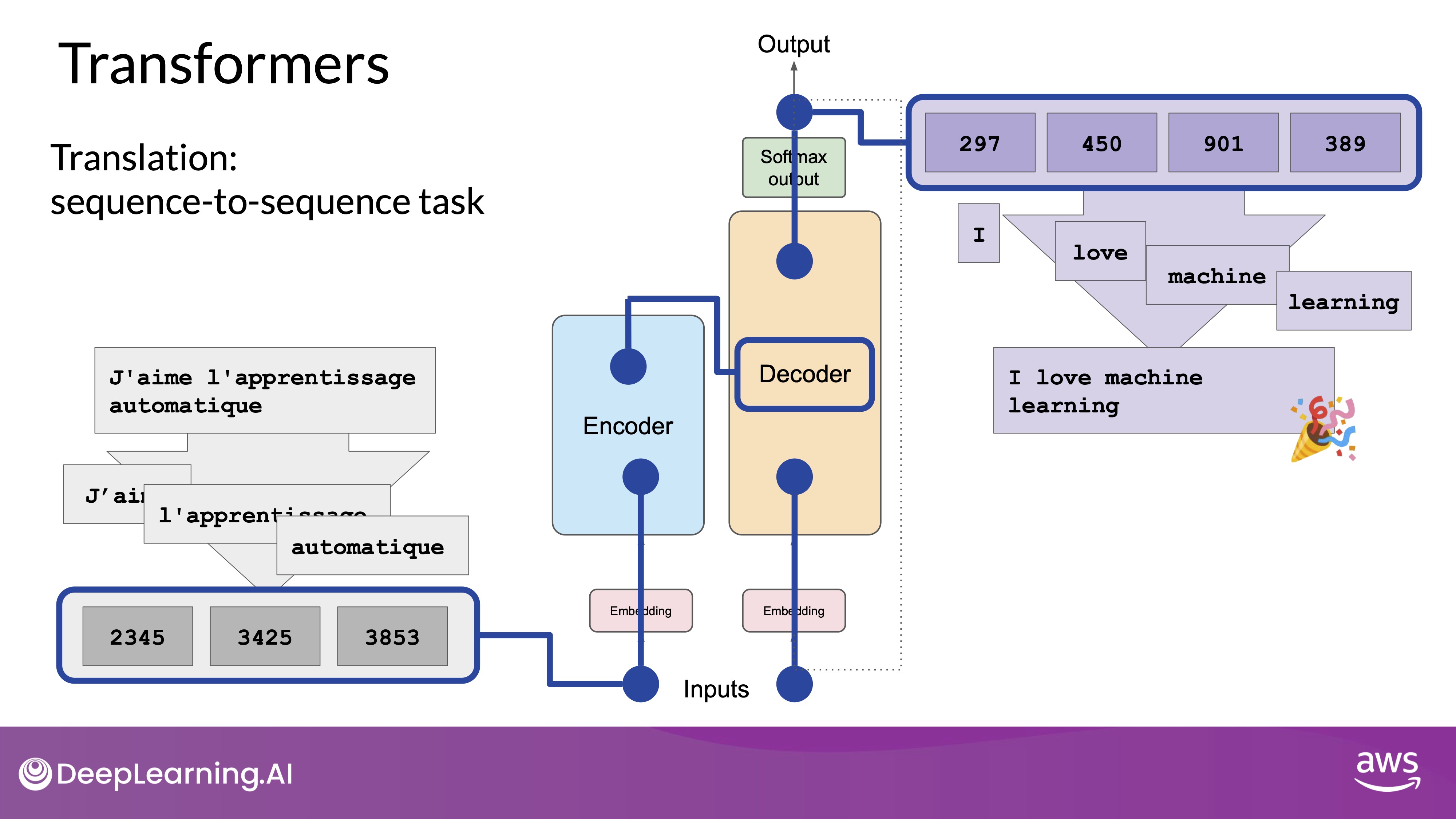
Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Decoder Process:
- The encoder's output influences the decoder's self-attention mechanisms.
- A start-of-sequence token is added to the decoder input.
- The decoder predicts the next token based on the encoder's contextual understanding.
- The decoder's output passes through self-attention layers, a feed-forward network, and a softmax output layer.
- Generation Loop:
- The first token is generated.
- This token is fed back into the decoder to generate the next token.
- This loop continues until an end-of-sequence token is predicted.
- Detokenization:
- The final sequence of tokens is converted back into words to produce the output text.
- A start-of-sequence token (often abbreviated as
[SOS]or<s>in tokenized form) is a special token that signals the beginning of the sequence generation process. - When the decoder starts its process, the
[SOS]token is added to the input to indicate that it should begin generating the output sequence. - This token helps the model understand that it should start predicting the first word of the target sequence.
Transformer Model Variations
- Encoder-Only Models (less common):
- Typically used for tasks where the input and output sequences are the same length.
- With additional layers, they can handle classification tasks like sentiment analysis.
- Example: BERT.
- Encoder-Decoder Models :
- It performs well on sequence-to-sequence tasks such as translation, where the input sequence and the output sequence can be different lengths. You can also scale and train this type of model to perform general text generation tasks.
- They can scale and perform general text generation tasks.
- Examples include BART and T5.
- Decoder-Only Models (commonly used):
- Commonly used for various tasks.
- Examples include the GPT family, BLOOM, Jurassic, and LLaMA.
Summary
- The complete transformer architecture consists of encoder and decoder components.
- The encoder converts input sequences into deep representations.
- The decoder generates new tokens based on the encoder's context.
- Different transformer models are suited for various tasks, such as translation, classification, and general text generation.
Prompting and prompt engineering
Interaction with transformer models is through natural language, known as prompt engineering.
Prompt Engineering
- Improving Prompts: Often, the model may not produce the desired outcome on the first try. Revising the prompt's language or structure, known as prompt engineering, is crucial to achieving better results.
- In-Context Learning: Including examples of the task within the prompt can enhance the model's performance. This technique is known as in-context learning. Examples of In-Context Learning includes
- Zero-Shot Inference:
- Providing only the task instruction and the input data.
- Example: Asking the model to classify the sentiment of a movie review with no prior examples.
- One-Shot Inference:
- Including one example of the task along with the instruction and input data.
- Example: Adding a sample review and its sentiment before providing the review to be analyzed.
- Few-Shot Inference:
- Including multiple examples to help the model understand the task better.
- Example: Providing both a positive and a negative review with their sentiments to improve the model's comprehension.
- Zero-Shot Inference:

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Larger models vs Smaller models:
- Larger Models:
- Larger models with more parameters capture a better understanding of language and perform multiple tasks well.
- Generally perform well with zero-shot inference due to their extensive training and understanding of language.
- Capable of completing tasks they were not specifically trained to perform.
- Smaller Models:
- Often require one-shot or few-shot inference to perform well.
- Better suited for tasks similar to those they were trained on. Thus is usually is referred as Task-Specific Models.
- Larger Models:
- Context Window: There is a limit to how much in-context learning can be passed into the model. If performance does not improve with 5-6 examples, consider fine-tuning the model instead. Fine-tuning performs additional training on the model using new data to make it more capable of the task you want it to perform.
- Once a suitable model is found, experiment with various settings to influence the structure and style of the completions.
Generative configuration at inference time
Generative configuration parameters are used at inference time to influence how a language model generates the next word in a sequence. These parameters are distinct from training parameters and provide control over aspects like the number of tokens generated and the creativity of the output.
- Using the below parameters, you can fine-tune the model's behavior to match your needs, whether it's producing highly creative content or sticking closely to likely word sequences.
- Experimenting with below settings can help you find the right balance for your specific application.
Key Configuration Parameters
- Max New Tokens:
- Limits the number of tokens the model will generate.
- It's a cap, not a fixed number, as the generation can stop if an end-of-sequence token is predicted.
- Example values: 100, 150, 200 tokens.
- Greedy Decoding (by default setting for most LLMs):
- The model selects the word with the highest probability.
- This method is effective for short texts but can lead to repetitive sequences. If you want to generate text that's more natural, more creative and avoids repeating words, you need to use the Sampling Techniques.

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
Sampling Techniques
- Random(-weighted) Sampling:
- Introduces variability by selecting words based on their probability distribution.
- Higher probability words are more likely to be selected, but randomness can lead to more creative or less coherent outputs.
- Note that in some implementations, you may need to disable greedy and enable random sampling explicitly. For example, the Hugging Face transformers implementation, you need to explicitly enable this by setting
do_sampletotrue-GenerationConfig(max_new_tokens=50, do_sample=True, temperature=0.5).
- Top-k Sampling:
- Limits choices to the top
ktokens with the highest probability. - Example: If
kis set to 3, the model will choose among the three highest-probability tokens, reducing the chance of improbable words while maintaining some randomness.
- Limits choices to the top
- Top-p (Nucleus) Sampling:
- Limits the selection to tokens whose combined probability does not exceed
p. - Example: If
pis set to 0.3, the model chooses from tokens that collectively have a 30% probability, ensuring a balance between randomness and likelihood.
- Limits the selection to tokens whose combined probability does not exceed
Temperature Parameter

Source: DeepLearning.AI - Learn the fundamentals of generative AI for real-world applications
- Adjusts the shape of the probability distribution for the next token.
- Higher temperature (greater than 1) flattens the distribution, increasing randomness.
- Lower temperature (less than 1) peaks the distribution, concentrating probability on fewer tokens, making the output more predictable.
- A temperature of 1 uses the default probability distribution.